Every commercial RTOS employs a priority-based preemptive scheduler. This despite the fact that real-time systems vary in their requirements and real-time scheduling doesn't have to be so uniform. Multitasking and meeting deadlines is certainly not a one-size-fits-all problem.
Though there are good reasons to use priority-based preemption in some applications, preemption also creates a number of problems for embedded software developers. Programming in such an environment necessarily creates excess complexity when the application is not well suited to being coded as a set of tasks that can preempt each other. Sometimes this added complexity results in system failures. It almost always also lengthens development and debug cycles.
The big question is: Are you choosing an RTOS for the right reason?
Priority-Based Scheduling
There is a relatively simple explanation for the observed regularity of RTOS designs: academia. In the 1970's and 1980's the concept of "fixed-priority scheduling" was widely studied. This research culminated in the canonical 1991 research paper: "Rate Monotonic Analysis for Real-Time Systems" by Sha, Klein and Goodenough.
David Stewart and I earlier wrote a concise overview of RMA.
In a nutshell, the rate monotonic algorithm (RMA) is a procedure for assigning fixed priorities to tasks to maximize their "schedulability." (A task set is considered schedulable if all tasks meet all deadlines all the time.) The RMA algorithm is simple:
Assign the priority of each task according to its period, so that the shorter the period of a task the higher is its priority.
RMA, the academics ultimately determined, is the optimal fixed-priority scheduling algorithm. If a specific set of tasks cannot be scheduled to meet all deadlines using the RMA algorithm, it cannot be scheduled using any fixed-priority algorithm.
Webinar: How to Prioritize RTOS Tasks (and Why it Matters)
Given this "optimality" of RMA, it was natural for operating systems vendors to offer products that provide fixed-priority preemptive scheduling. Once Ready Systems' VRTX and a few other early RTOS players made a space for this technology, the other major market participants quickly followed suit.
The herd behavior had begun: a technique that solves one kind of problem best became the norm. Other kinds of problems would need to be solved by the brute force of fitting a square peg into the round hole of priority-based preemption.
Despite the fact that all our RTOS choices are designed for compatibility with RMA, these facts persist: few engineers are working on problems with hard real-time deadlines; very few folks outside of that group are using RMA to prioritize tasks; and measuring the worst-case execution time of each periodic task and finding a way to calculate the worst-case behavior of aperiodics (e.g., interupt service routines, or ISRs) needs to be done at each recompile and is so labor intensive it is probably only done on less than 1 in 10,000 embedded projects that use an RTOS.
Implications of Preemption
Aside from RMA compatibility, the one positive implication of preemption is task responsiveness. A preemptive priority-based scheduler effectively treats software tasks as hardware treats ISRs. As soon as the highest-priority task (ISR) is ready to use the CPU, the scheduler (interrupt controller) makes it so. The latency in response time for the highest-priority ready task is thus minimized to the context switch time.
(For a more detailed explanation of preemption read this.)
By contrast, there are at least ten negative implications of preemption, as indicated in Figure 1 below.
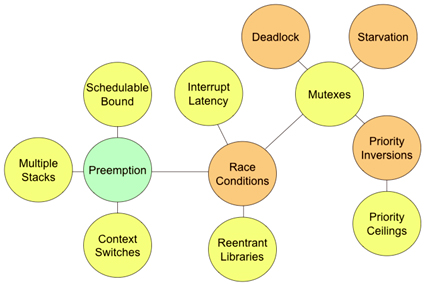
Figure 1. Ten negative implications of preemption
The figure shows how these implications ripple out of the "Preemption" node. As we talk about what these implications are, you'll see that these are the very problems we encounter Let's start our analysis with the simple stuff. For example, the three yellow bubbles immediately surrounding the Preemption bubble are Schedulable Bound, Multiple Stacks, and Context Switches. Yellow is meant to indicate that, though these are serious issues, they are more annoyances than the Orange-colored system failures.
First-order Implications
The Schedulable Bound implication refers to the fact that to gain the maximum benefit from RMA, the user must be willing to give up use of up to 31% of CPU cycles. That is, the CPU-intensive work to meet all the deadlines for all N tasks in your system is limited to 69% (ln 2, to be precise) CPU utilization. Put another way, you'll need to pay for about 45% (31/69) more CPU cycles than you'll actually use.
The Multiple Stacks implication goes like this: If your system will have ten tasks and preemption is present, then all ten of those tasks needs to have its own private stack space.
Because stack space must be allocated on a worst-case-ever-needed basis, this requires the use of up to 10 times the amount of RAM that would be required to complete the same set of work in the absence of preemption. And unless you have also a distinct "interrupt stack" for processing worst-cast ISR nesting, each of the ten task stacks must be that much larger.
The third immediate resource wastage implication of preemption is the need to perform a "Context Switch" each time preemption occurs. The process of performing a context switch varies by processor, as some CPUs are set up to handle this rather efficiently.
In the typical case, however, the CPU must effectively push the contents of all its registers and flags into RAM, then pop the same type of information for the next task from another RAM storage area. This wastes CPU cycles in addition to those already out of reach because of RMA's schedulable bound.
A fourth and more dangerous preemption implication is the ubiquitous Race Condition. In real systems, tasks do not execute in isolation from each other. Real tasks need to share data to get work done. In a system that lacks preemption, there is no risk of tasks corrupting data in the process of sharing it.
A good analogy here is of two co-workers who share the same job and office, but work on alternating days. Though Worker A and Worker B each operate on the same files, there is no chance for the files themselves to be corrupted in the process.
A pair of tasks running in a preemptive RTOS and manipulating the same areas of RAM or hardware registers, though, will create numerous opportunities each second for data corruption. There are at least three second-order implications of race conditions: Interrupt Latency, Reentrant Libraries, and Mutexes.
Second-order Implications
Interrupt Latency increases in preemptive systems as a result of the potential for race conditions. The issue here is that there are potential race conditions within the OS itself. For example, in order to select the highest-priority task to run, the scheduler must keep an internal linked list or other data structure with information about each task that wants to use the CPU.
To prevent these internal data structures from being corrupted by interrupts that result in system calls, interrupts must be disabled during every critical section of OS code that touches these data structures. Interrupt latency for the system as a whole increases by the worst-case length of an OS critical section. In a nutshell, systems with an RTOS respond more rapidly to software tasks but more slowly to hardware interrupts.
Since the application code in several tasks may call the same shared library routines, such as a driver for a UART, it is possible the task preemption will take place inside one of those shared functions. To prevent race conditions from occurring in the shared library routines, that code must have its critical sections identified and protected. That means that every shared library routine must be made reentrant, meaning both longer (more code space) and slower to run.
Finally, as a workaround for race conditions in the tasks and shared library routines (which cannot safely disable interrupts), a new OS primitive is required: the mutex (a.k.a., binary semaphore). Mutexes provide a rather nifty way of protecting shared data from race conditions.
To use them, programmers first identify shared data and the critical sections of code in each task that uses that data; next they create and associate a mutex object with that shared data; finally, they surround each critical section with calls to "take" and "release" the mutex. The only problem with mutexes is that you shouldn't actually use them in practice.
(Despite what you learned in Operating Systems class, the right way to share data between tasks is to use mailboxes to send data from one task to another for the next stage of processing in an always-safe manner. You should always keep redesigning your task interactions until you don't need a single mutex to get the job done.)
Serious Consequences
Mutexes do solve the race condition problem quite nicely. However, mutexes are fraught with negative implications of their own: Starvation, Deadlock, and Priority Inversion - all of which are ultimately associated with difficult-to-diagnose product lockup and failures in the field.
Put simply, Starvation is the death of one task. The affected task withers on the vine unable to make progress because it never is able to obtain a needed mutex. The trouble here is the whole priority-based scheduling paradigm. A second-tier task may never be selected to run if some higher priority task is always using the processor. It's called starvation if this condition exists for any length of time that prevents proper operation of the affected task.
Deadlock involves two or more tasks and is also known as a "deadly embrace". Any text about operating systems will tell you more about deadlocks. Suffice it to say that the problem here is circular blocking; Task A has a mutex Task B is waiting for, and vice versa. Neither task will ever be able to progress and those tasks can only be restarted via system reboot.
Finally, there is the implication of Priority Inversion. Priority inversion is more subtle than starvation or deadlock. In short, a medium-priority task prevents a high-priority task from using the CPU by preempting a low-priority task that holds the mutex needed by high. This is a system failure because it violates the basic assumption of priority-based preemptive scheduling: The highest priority ready task is NOT using the CPU for the length of the inversion—the length of which may even be unbounded because of potential starvation of the low-priority task.
(For more details on Priority Inversion including a helpful diagram read this.)
Several workarounds to priority inversion exist, but they always result in wastage. For example, under the Priority Ceiling Protocol each shared resources has a priority at least as high as the highest-priority task that ever uses it. Unfortunately, this popular workaround results in another violation of the basic assumption of priority-based preemptive scheduling: A medium priority task may NOT use the CPU because a low-priority task is running and using a resource sometimes used by a high-priority task.
Conclusions
Many embedded developers vastly underestimate the true costs and skills needed to program with a preemptive RTOS. The truth is that all traditional RTOS mechanisms for managing concurrency such as semaphores, mutexes, monitors, critical sections, condition variables, event flags, and others are tricky to use and often lead to subtle bugs that are notoriously hard to reproduce, isolate, and fix.
There are several useful alternatives to priority-based preemptive scheduling, ranging from infinite loop cyclic executives to run-to-completion processing kernels.
The "killer app" for the existing crop of RTOSes is a set of tasks that are each similar or identical to their brethren and running without interaction among tasks. In this type of design, the preemptive scheduler serves the function of load balancer. Examples of such applications are an embedded Web (HTTP) server or any telecom/datacom switch with multiple channels.
Many other types of applications are poorly served by priority-based preemptive scheduling. Trying to fit the square peg problems into the round hole of a commercial RTOS leads to frustration, bugs, and overly-complicated designs.
So next time you're trying to figure out why your system just locked up unexpectedly in the lab or in the field, spend some time thinking about why you chose an RTOS. If you aren't in need of the one positive thing from priority-based preemptive scheduling, why are you paying the price ten-fold!
This article was published at Embedded.com in January 2006. If you wish to cite the article in your own work, you may find the following MLA-style information helpful:
Barr, Michael. "Multitasking Alternatives and the Perils of Preemption," Embedded Systems Design, January 2006.