Understanding software and hardware bugs in other embedded systems can help you identify, diagnose, and fix bugs in your own.
Legendary bugs are the software engineer's war stories. While the rest of the human population would sooner chew on broken glass than listen to an anecdote that ends with "... and then I realized foo should have been a 16-bit counter, ha, ha, ha!," other engineers love to hear about the nasty tricks our code can play on us. In this article, we'll explore some of the more insidious bugs that I've encountered over the years, sometimes as the author, sometimes as the fixer, and sometimes as an interested observer.
While none of these bugs caused much harm, they illustrate interesting quirks. Along the way, we'll see some of how the C preprocessor works and I'll give some warnings on the use of timers.
Side Effects of Compiler Optimization
The first set of bugs involves changes that should make no difference to the behavior of the system, but mysteriously they do. Optimization options are meant to make no difference to the behavior, except in terms of execution speed and size. In a real-time system, making certain portions of the code faster may expose a race condition, but there are other subtle effects of optimizations that can catch you out.
Many compilers have an option that permits you to save space by keeping only one copy of identical strings. For example, if the character string "hello" appears in three places in the source code, only one copy is stored and all the other places in the code that use that string will refer to that copy. Because this technique is only applied to constant strings, there's no danger that one reference to the string will modify it.
On one occasion, my coworkers and I found a bug in our code that had not been in a previous version. We examined the changes from the previous version to the current one, and narrowed it down to this compiler option. Closer examination of the code showed that some sloppy practice had left us vulnerable to the effects of this optimization. Listing 1 shows a simplified version of what we were doing.
x = "hello"; // hello1
// more code
if (leaving == TRUE)
{
y = "goodbye";
}
else
{
y = "hello"; // hello2
}
if (copying == TRUE)
{
y = x;
}
// more code
if (x == y)
{
identical();
}
Listing 1. The compiler may make small changes to this code
The final if statement compares two pointers. There are two hard-coded copies of the string "hello". We'll use hello1 and hello2 to refer to their locations in memory. After too many days of using C++ string classes where the == operator was overloaded to compare the contents of the string class, I had applied the same logic to raw C char pointers. The == operator on the pointer does not check if the strings are the same. Instead, it is checking if the pointers point to the same place. With the optimization turned off, hello1 and hello2 are different locations and so even if x points at "hello" and y points at a copy of "hello" stored in a different location, the final if condition will be FALSE.
Now, turn the optimization on and the behavior will change. Because the string at hello1 and hello2 are identical, the compiler stores one copy of "hello" and both hello1 and hello2 will refer to that location. Now, executing the lines x = "hello" and y = "hello" lead to the final if having a TRUE result.
As with many subtle changes, turning this optimization on or off would have been completely benign were it not for another bug in the code: the fact that if (x == y) was not the right type of comparison. It should have always used strcmp( ) or some equivalent.
Boundary Conditions
In the film Jurassic Park, there is a scene in which Jeff Goldblum's character discovers that their method of checking if all the dinosaurs are present is to count the number of animals and once they reached the expected number, they stop counting. The fact that the number of dinosaurs was increasing wasn't noticed because they never tried to count more than the expected number of dinosaurs. The clever critters had figured out how to breed, in spite of the fact that all of the cloned dinosaurs were supposed to be female.
Goldblum's character suggests that the computer search for a far greater number of dinosaurs, and when the number of animals actually found goes beyond the original number, the group realizes they have far more prehistoric animals than they ever expected. I call this the Jurassic Park bug. It's the mistake of setting an upper limit on a value, believing that a greater number cannot happen or won't matter if it does happen. It's a shortcut that often makes programming easier but can cause unexpected states to be invisible to the system.
Would your software make the same mistake? If you're storing a number in an 8-bit value, you have to stop counting at 255. You could consider this value to be an error state, or you could stop incrementing and leave the value at 255, as an approximation of the biggest count that is possible in the system. Which option is best depends on whether the counter only reaches 255 in an error state or as a normal occurrence.
When using scaled arithmetic, it can be useful to cap values so that calculations using out of range values won't lead to overflows. In one case, we limited a measured gas flow to 25L/min. Since the system typically controls to 15L/min, we figured that even if we did experience flows above 25L/min, treating them as equal to 25L/min would be fine for our purposes.
In some cases, the flow did exceed 25L/min, but we assumed that it wasn't important to measure those cases because we weren't in a control situation. One such case was a test that compared flows detected by two identical sensors. Assuming the sensors were functioning correctly and calibrated, the flows at each sensor should have been within a tolerance of each other. When the external gas supply pressure was very high, it was possible that this test would take place with more than 25L/min flowing through the system. Assuming that the calibration on one sensor had drifted, the flows measured by the two sensors were, for example, 26L/min and 29L/min. Both of these values were then truncated to 25L/min for the reasons I described earlier. When it was time to compare the two readings, they were both equal to 25L/min and therefore equal to each other. The comparison test was disabled for flows above 25L/min.
In the case of the comparison test, we chose to limit the flow readings in software to 25L/min. Even if you do not limit the reading in software, the hardware may impose limits on your design. For example, the output voltage of a sensor will have an upper limit that caps the flow reading. It would be nice to suggest that you should always use sensors with a range wider than your system will ever experience. However, keep in mind that you'll have to trade widening the range of the sensor for sensor resolution. A sensor with a smaller range and greater resolution may give you better accuracy but leaves you with a blind spot where you can't see what is going on.
I occasionally see the Jurassic Park bug in event logs. Consider a device that records exceptional events in a log. There is limited space to store the events, so a log of 30 entries is created. Each entry is a structure containing details of the event type, time and perhaps the current settings of the device. A full log contains 30 events. However, if 50 events have occurred then the log still contains 30 events, so the true nature of the number of events has been hidden. In this case, the problem can be alleviated by having one final entry that contains a count of the unrecorded events. While this does not give you details of the events, at least you know that you are missing something. As the device is used, this counter may give you an indicator as to whether there would be value in investing in more log storage space.
There are many other variations of the Jurassic Park bug. Now that I've suffered from it a few times, I'm much more reluctant to limit a value at some maximum. I prefer to find a limit where I can declare the system to have failed if the limit is exceeded.
Side Effects of Comments
One of my colleagues was working on the checksum that we used to ensure that updated copies of our software had been downloaded without corruption. He was noting the checksum values for each executable as part of his testing. He came to me complaining that he had found what he thought must have been a compiler bug. Because this compiler had so many bugs, another one wouldn't have surprised us.
He had changed a comment and the checksum was now different to its previous value. In a sane world, changing a comment should have no impact on the generated code, and therefore the checksum should have turned out to be identical before and after the comment change. I immediately assumed that some compiler option had changed, which could have changed the output without any change to the source code. But there had been no changes. I asked if a different PC had been used to compile the program—we could have had an older version of the compiler installed somewhere. But this was not the answer either.
We had a version number stored in the code. On some of our projects, this number updated automatically with every build, and therefore no two compiles would be identical. On this project, however, the number changed only when the programmer manually edited the file. On this occasion, it hadn't been changed, and so was not the cause of the differing checksum.
I started to think that the date stamp could have been inserted at some point of the executable. This might have been a feature built into the compiler. The what command in Unix supports such a technique, so it was possible that this compiler vendor had implemented something similar. If the date stamp was being stored in the executable, it would change the checksum even if the date stamp was never accessed by the running code. I trawled the compiler manual and could find no reference to such a technique. We eventually eliminated the impact of the time of day by simply compiling again with no changes. Time had moved on but the checksum stayed the same, so the problem was not a stored time stamp.
Using a differencing utility, we checked where in the code the changes took place. If we could pin it down to one location in the binary file, we might be able to trace it back to the source code. The changes were many and small and scattered throughout the module that contained the comment change. This looked like an optimization flag change, since that is something that would have an effect in many places, but we had already eliminated that possibility. The size of the code had not changed at all, which also suggested that optimizations were not the cause.
I had another look at the comment that had changed. One extra line had been added to a block of text. This should not change the meaning of the program, but it does change line numbers. Then it dawned on me. We used the assert() macro extensively. (See "Assert Yourself" for background on the assert( ) macro.)
This macro uses the compiler's built-in __LINE__ macro, which equates to the current line of the file being compiled. If we changed the line numbers then the __LINE__ value used by each assert() would be different, and those values are stored in the executable file.
So, the changing checksum mystery was solved. In fact, this turned out to not be a real bug in the end, since it was not a problem so long as the programmers were aware that comment changes could have this effect.
Unexpected Compiler Behavior
In the last section, we suspected the compiler vendor, but they were innocent. Unfortunately, that is not always the case, and compiler bugs can be very difficult to isolate, not least because the developer generally doesn't have access to the source code of the compiler.
A number of years back, we had a compiler that regularly reported syntax errors on the wrong line of the source code. This was a bit of a nuisance, but if you searched backwards from the point where the error was reported by the compiler, then you could usually spot the line where the error actually existed. In some cases, the error was reported on the correct line; sometimes, the location was wrong by 10 lines or more. As the project progressed and files got bigger, the problem seemed to get gradually worse. We also found that having the lines out-of-sync was affecting our debugger. As we stepped through the code, the source line reported was not the one that was executed. This was much more serious than misreporting the location of syntax errors, since it was now impossible in some cases to establish the execution path of the code.
The compiler vendor assured us that the lines were out of step because of optimizations that eliminated or shortened some of our execution paths. This might have been a plausible explanation for the problem in the debugger, but it would not have explained the syntax error location being misreported.
Again the __LINE__ macro enters the picture. In some cases, like the assert() macro discussed above, the __LINE__ macro is being used by the application programmer to report the location of events at run-time. However, the compiler can also use this macro for some of its internal house keeping. The value of __LINE__ can be changed with the #line directive. In fact, if you do not like the way the compiler numbers the lines in the file, you can change the line numbering with:
#line 2000
Sneak one of these into your colleague's code just before he starts compiling it and watch the fun as all of the syntax errors are reported on the wrong lines.
Code that is generated by the compiler can use these #line directives to keep the line numbering in the generated file in sync with the original source code. This technique used to be common in C++ compilers that generated C code. The C code included a #line directive at the start of a block of code that represented a single line of C++. Typically, the C file was far larger than the original C++ file, but the #line directives meant that the reported line number provided the user with the correct location in their original C++ source to locate the file.
A similar technique is used by cpp, the C preprocessor. The preprocessor expands all macros, removes all comments and inserts the contents of any files that have been specified with the #include directive. The result of these steps is stored in a single file that is then fed into the compiler proper.
Of course, this single file is much larger than the original file, since there may be many included files. The output of cpp is usually a temporary file that the user may never see, but most compilers will give you the option of preserving this file if you need to examine it. This is what I did in my efforts to find out why my line numbers were never quite right. Listing 2 shows two small files and the output generated by cpp. Within each header file, the #line directive is used to indicate the line and file name that should be reported when there is an error.
header.h
// This is a header
typedef int B;
c.c
// This is a C file
// with one function
#include "header.h"
void foo(void)
{
// do nothing
}
Output of cpp run on c.c
#line 1 "c.c"
#line 4 "header.h"
typedef int B;
#line 4 "c.c"
void foo(void)
{
}
Listing 2. Two small files and the output generated by cpp
For example, if there was a mistake in the typedef in header.h, the #line directive tells the compiler that the current line, from the user's point of view, is Line 4. The #line directive takes an optional second argument that specifies the filename. This step is necessary since we need to distinguish the header files from each other and from the C file after they have all been merged in the output of cpp.
The problem seen by examining this file is that the #line directive following the header file indicates that the next line should be Line 4, when in fact the following line is the fifth line in the original file. From this point forwards, all of the source is out of step by one line. If we include another header file, the error increases to two lines. Some header files had this effect and others did not. Eventually, the difference between the header files was pinpointed as an issue with the last line of the files. The editor we were using allows us to have a final line in the file that doesn't have a carriage return. The vendor's version of cpp didn't increase its line counter unless there was a carriage return. To keep track of line numbers correctly, the last line in the file must be followed by a carriage return that is then followed by the end-of-file marker. Many editors enforce this, so some users would never be exposed to this bug. Our editor, CodeWright, allows the final line to end without a carriage return, so we got caught out.
We couldn't convince the compiler vendor that this was worth fixing. Some versions of cpp don't tolerate a line with no carriage return, but they report it as an error, which is much more acceptable, since you immediately know the source of the problem. We manually checked all of our header files to ensure that the last line was always followed by a carriage return and all of our line synchronization problems went away.
Initial Conditions and Transitions
Sometimes, reading a simple input line can become tricky if you don't consider the initial state of the signal. On a recent project, we had a circuit that compared our battery voltage with a reference voltage. The output of the comparator provided an input line to the microcontroller indicating whether the battery was charged well enough to continue using it. The signal was attached to a dedicated input line of the microcontroller where it was latched into a register, until cleared by software. The latch detected a falling edge on the signal. The signal is called BATT_LOW.
The line could have been connected to an interrupt, which was the original intention of the hardware design. Since the battery voltage falls slowly, a speedy response from an interrupt isn't required, so using a regular poll from the main line was chosen instead. The bug I'm going to describe would have occurred whether the line had driven an interrupt or had been polled.
Software turns off the system when the battery is low, if the system is being powered by the battery. The system also runs on mains, in which case we ignore the BATT_LOW bit. When the system is running on battery, we poll the BATT_LOW bit and if it's ever high, we shut down the system.
We found that there were cases where we would switch from mains to battery supply and the system would run after the battery had gone far below its rated voltage, where BATT_LOW should have triggered the system to turn off. Running on such a low battery could cause the system to behave in an unpredictable manner. Other times, it would turn off exactly when planned. By monitoring the BATT_LOW bit, we realized that the bit was never set in the failed cases. The problem was that if the battery was low when we started on mains, it never had a chance to transition to the low state since it was already low, and therefore the edge-triggered latch never got set. There was no edge and therefore no indication that the battery was bad.
There were two causes for this bug. Making the signal edge-triggered was not appropriate in this case. When the decision was made to not use an interrupt, it would have been more appropriate to redesign the circuit to detect the state of the battery, rather than using a signal that latched a transition. The second problem was that we did not consider the initial state of the signal that we were going to latch. We foolishly assumed that we would always start with a good battery, since we had not run it down yet. Of course, the battery could have been run down from previous use. If we switch on using mains power with the battery still low, we have a scenario where the signal starts in the low state and therefore never has the opportunity to transition from high to low. If there is no transition, then BATT_LOW is never set since it is an edge-triggered bit.
Unsynchronized Counters
Programmers love to put constants into #defined values or const int declarations. It usually affords them the luxury of being easily able to change the value later, without feeling that they have really changed the code or the algorithm.
It's still important to realize that changing a value can have a more dramatic effect than intended. We had a system that used delays while we waited for certain pneumatic conditions to stabilize. One part of the system required a three-minute delay. Because we had a counter that incremented every minute, we defined a value of three as the WARMUP_DELAY. At the start of the delay, we recorded the minute counter as DelayStart. Once the minute counter reached the value DelayStart+3, the delay was over.
The counter was updated once per minute so our measurement of time had one-minute resolution. Our delay was started at a time that wasn't synchronized with those updates, so the actual delay was between two and three minutes, as seen in Figure 1. This delay wasn't a problem since its length wasn't crucial. In fact, as long as the delay was longer than about 20 seconds, everything worked fine.
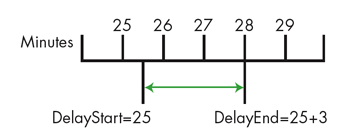
Figure 1. A delay of three actually lasts between two and three minutes.
Later on in the project, we were trying to reduce the time that the system waited for some of its pneumatic transitions. Three minutes was a long time for the WARM_UP delay, and I happily reduced it to one. At the time, I didn't consider that a value of one really meant a time less than or equal to one minute. This meant that in some cases the delay was less than 20 seconds, which caused the system to fail. The time period varied depending on how close the start of the delay was to the point where the minute counter was incremented. So the problem was sometimes present and sometimes not, making it tricky to track down.
The moral of the story is that the resolution and context of use should be considered whenever constants are changed. After I discovered my mistake, I realized that this issue of counters providing timers of limited accuracy is the same as you will encounter if you use timers provided by an RTOS or a counter that is incremented by a timed interrupt. Usually those timers would be measuring milliseconds rather than minutes, but the principle is the same: if a counter is used to measure time, and the delay is started at a time that is not synchronized with the counter's increment, the delay could be inaccurate by up to one tick of the counter.
Physical Considerations
This final example is my favorite because it demonstrates how easy it is to plan the software without giving enough consideration to the way in which the device will be physically handled. These are the sort of issues that make embedded software more interesting that the equivalent PC software.
As a power-saving method on a medical device, we had a "dim" mode that reduced the intensity of all of the LEDs and backlights on the front panel. Because the device would often be used at night in hospital wards, the dim mode served the purpose of saving battery life as well as being less intrusive in a room where the lights had been turned down while patients slept. The plan was that when light levels were low, the software would invoke the dim mode. In the morning, when the sun rose or the lights were turned on, the front panel would return to its normal intensity. The only hardware required was one simple phototransistor placed against a small clear window on the front panel.
In practice, we found that the device often went into dim mode at unexpected times. The times were not random. In fact, it seemed to happen when the user was interacting with the device, rather than at times when it was idle. A little bit of observation revealed the cause. The opening where the phototransistor is exposed was near to the middle of the front panel. Whenever a right-handed user put their hand on a button to the left of the opening, the opening was shaded by their hand, making the device think that night had fallen. Even though the signal had been debounced, there wasn't sufficient debouncing to accommodate a shadow cast by a person's hand for a few seconds, which was often the case as they pressed a number of buttons in the area to the left of sensor.
The solution was straightforward: we increased the debounce time significantly. We also ignored any transitions in the signal that took place within a couple of seconds of a key press. Ideally, we would also have changed the location of the sensor, but by the time we discovered this problem, the hardware was at an advanced stage and it was more pragmatic to get around the issue in software.
Bugs like these all follow patterns that repeat themselves in different projects, written by different programmers. Understanding bugs that you've encountered before, whether your own, your colleagues', or bugs that you read about, will help diagnose new bugs. Happy bug squashing.
Related Barr Group Courses:
Firmware Defect Prevention for Safety-Critical Systems
Top 10 Ways to Design Safer Embedded Software
Best Practices for Designing Safe & Secure Embedded Systems
Best Practices for Designing Safe Embedded Systems
For a full list of Barr Group courses, go to our Course Catalog.


