The information that a user gets from a life-critical system may spell the difference between a slight mishap and a serious accident. This article addresses the issue of safety in the design of a user interface.
Sometimes the worst accidents take place on perfectly functioning hardware and software that the operator simply misunderstood or misused because of a deficient user interface. When you analyze the safety properties of a system, it's important to ensure that the design is both true to the safety requirements and robust enough to tolerate certain failures. The design of the user/device interaction is particularly important. Enhancing safety through correct design of the user interface is the focus of this article.
Safety is a system property that resides in the device and in the people using that device. A passenger aircraft is safe only so long as the pilot doesn't decide to fly it into a building. The safety of the device itself depends on sufficient testing and fail-safe mechanisms that protect the users (and others) when some component, either software or hardware, does fail. Given a safe device, the user can maintain that safety only if he acts responsibly and can interpret the information displayed by the device. Because device integrity can be violated by people who disable sensors, ignore alarms, or use the device improperly, a system's safety depends on the user taking ultimate responsibility. That's why you're unlikely to see unpiloted passenger aircraft in your lifetime. Although the technology already makes it possible, passengers simply will not put faith in a system unless a user with the appropriate knowledge and skill is prepared to put his or her life at the same risk experienced by the passengers.
The operator is often a scapegoat for a badly designed user-machine interface. But it would be unfair to blame an operator for ignoring an alarm from a device that issues several false alarms per day, or for misinterpreting information that is displayed in a nonintuitive fashion. You may assume that safety-critical devices are operated only by trained personnel. But how true is that assumption? Consider driving a car—a deadly weapon if not properly controlled. The law requires that you pass a test before you're permitted to drive; however, the law does not require that you drive only the car that was used during the test. The interface in another car may be considerably different. Similarly, highly trained doctors and nurses use hospital equipment, but their training is mostly in the principles of medicine. They aren't necessarily trained to use every brand of equipment. You can expect the trained user to understand principles, but don't expect that same user to know that alarm volume is hidden under menu item three on your device.
Even a perfectly functioning device may contribute to a safety hazard if information isn't presented intelligibly to the user. Three types of information must be presented clearly: direct feedback to actions taken by the user; monitored parameters of the system; and alarms that alert the user, usually audibly, to unusual patterns in the monitored data.
Unfortunately, increasing safety often reduces the quality of other desirable properties of the system, in areas such as cost, performance, and usability. For this reason, it's important that the person ultimately responsible for a project's safety has a minimal investment in the other properties such as cost, timeliness, or usability of the system. Maintaining an organization in which this is the case is no trivial matter. In very small organizations, it just isn't feasible to dedicate a person solely to the role of safety, though in some cases it can be combined with testing. The goals of safety are compatible with those of testing in that they both attempt to detect and eradicate any shortcomings of the product, and they may push out the launch date, in return for increased quality. Testing, however, tends to emphasize finding points where the implementation doesn't meet the specification. The safety engineering role tries to ensure that the specification defines a system which is safe. Software bugs make spectacular headlines, and public perception may be that failures of implementation are the predominant cause of computer-related accidents. However, incorrect specifications have caused more accidents than software bugs have.1
The user interface is the place where unsafe actions can most effectively be rejected and unsafe states can be announced. If all of the safety mechanisms are buried deep within the system, it may be difficult for the user to diagnose the problem. When an accident occurs, quick and accurate diagnosis of the failure may be vital.
The usability vs. safety trade-off
Although it may seem intuitive that a device that is easy to use is safer than one that isn't, that is not always the case. To provide safety, you must often make the user work harder. Many situations involve a direct trade-off between usability and safety. Take the Therac-25, which was a cancer irradiation device whose faulty operation led to a number of deaths. One of the safety features in the original design was that all the settings for the device had to be entered through a terminal, as well as on a control panel. This was seen as redundant by users of a prototype, so the design was changed before release so that the settings could be entered on the terminal alone. Once the settings were accepted by hitting the Return key, the user was asked to confirm that the settings were correct—by hitting the Return key again. This extra step was considered a replacement for the original second interface.
Unfortunately, users started pressing the Return key twice in succession, as a reflex. With repetition, the action became like double-clicking a mouse, and thus the settings were never really reviewed. Because of a bug in the software, though, some settings weren't properly recorded. The bug was a race condition created because proper resource locking of the data wasn't exercised. Since the cross-check had been removed, the fault wasn't detected. So here was a case in which the design was altered to favor usability, but the safety of the device was fatally compromised.
If the rest of the design had been sound, removing the second set of inputs would not have been significant. But the point of putting a safety infrastructure in place is to allow for the times when something does go wrong.
Note too that the later design was more susceptible to the simple user error of entering a wrong value. If the user has to enter the value on two different displays, the chances that the same wrong value will be entered are slim. The software would detect the mismatch and not apply either setting. Often, safety measures can serve this dual purpose of protecting against device error and user error. In intensive-care medical ventilators, for example, the pressure rise in a patient's lung is a function of the lung volume and the volume of gas added. A pressure valve opens at a fixed pressure limit. Once the valve is open, an alarm sounds and the patient is exposed to room air pressure in the fail-safe state. This feature protects the patient against an electronic or software fault that may deliver a large volume of gas, as well as from a user accidentally setting 3.0 liters rather than the intended 0.3 liters.
I'm not necessarily advocating that users be required to enter data twice on all systems; in some cases, simpler measures will suffice. Limits can be placed on input values or may be set based on other known information—perhaps a patient's weight may limit the amount of medication that can be delivered. A numeric keypad may allow the risk of a decimal point being entered in the wrong location, which might cause a setting to be wrong by a factor of ten. If the user rotates a dial to select the value, this slip will be less likely. If default values are provided, the user may be forced to select each of the defaults to minimize the chance that the user will proceed without considering if each of the values is appropriate. Each of these steps will provide a more robust system, in which the user is less likely to accidentally enter settings that he or she would never have consciously chosen.
Validating input
If the user can easily perform irreversible actions, a mistake may have serious consequences. The system must make it obvious that an important action is about to take place. Asking the user to confirm an action is common, but not necessarily the best approach. Sometimes, making the action different from usual user actions is enough. A piece of medical equipment might have an "Apply to patient" button that would be pressed only when the adjusted settings are to be made active on the patient. This button can be placed a distance from the other input controls, just as the power switch on a desktop computer is not placed on the keyboard.
In other cases, the system can attempt to guarantee that risk has been removed before proceeding. On paper-cutting machines used in printing shops, there is a risk that the blade that cuts the paper will drop while the user's hands are still moving the paper into position. You can remove this risk by placing two buttons on either side of the machine, which the user must press simultaneously to lower the blade. The user cannot press both buttons simultaneously if either hand is in the path of the blade.
Another aspect of this problem is that the device must know when it's safe to continue operating in a certain mode, in the absence of further instructions. Some devices employ a dead man control, which reverts to a safe state when force is removed. You may have noticed these controls on devices as simple as a lawn mower. As the user pushes the lawn mower, he or she must hold a lever against the mower's push-bar. When the user releases the handle, the mower stops. This control reduces the chance that the user will place his hands or feet near the blade while the mower is running. In a case in which an incapacitated operator can lead to a dangerous situation, you should employ a dead man control.
While some situations offer a neat solution, safety often depends on a sequence of actions. The system should be capable of reminding users of incomplete actions. Pilots have been known to place paper coffee cups over a control they must revisit before they complete the current task. Try to make the interface's appearance different during a setup operation than during normal running so that an incomplete setup will be immediately recognizable. If the user leaves a task incomplete, you can use an audible tone to get the user's attention; the user must then either complete the sequence or cancel it to silence the tone.
Some equipment silently times-out by canceling an incomplete action. Time-outs guarantee that the device isn't left in a state waiting for one final key press to acknowledge an action that was partially entered at some earlier time, possibly by a different user. However, this type of time-out presents several problems. The initial steps may be canceled while the user is deciding which step to take next. Estimates for the time it takes to read a screen may be optimistic, for example, if the designer assumes the user is a native English speaker. Even a time-out of several minutes isn't long enough if the user decides to consult a manual or a colleague. The user could put the device into a confusing state, only to have it cancel out of that state by the time the local expert sees it. Another danger is possible if the time-out occurs just as the user moves his or her finger toward the final key of a sequence. The user may not be sure which occurred first, the time-out or the completion of the sequence, and wouldn't know whether the input changes have taken effect.
Construct dialogs that are clear and unambiguous. On one device, I displayed the message "Press ACCEPT or CLEAR" when the user had been offered the choice between confirming or rejecting a change. However, the Clear key was to the left of the Accept key. This could lead to confusion, as the word Clear is to the right of the word Accept in the text message, as shown here:

Figure 1. Mismatched message text and button placement can confuse the user.
Note that this example also breaks the earlier rule that the Accept and Clear keys should not be near each other. That mistake was made, then the confusing text messages compounded the error. There exists a danger that the first-time user may press the wrong key once before learning the correct layout. Although the confusion caused here may seem slight, the greater danger occurs when a user reacts to an emergency and follows the wrong impulse, thus pressing the wrong key. A state of emergency is obviously the worst time to make a mistake; in this case, it is also the most likely.
Monitoring
Monitored values are the user's window into the process. The monitored values should tell the user the state of the system at a glance. An alarm that only detects whether the settings are being applied isn't sufficient in a safety-critical system, partially because the set parameter may not be the appropriate value to monitor. For instance, a pilot uses the throttle to set the amount of power that the engine consumes. The air speed is monitored to inform the pilot of progress. Factors such as rate of ascent affect the air speed, though, and cannot be factored into the throttle setting.
Another problem with relying solely on settings and alarms is that alarms simply can't react quickly enough. If you set alarm bands so tightly that a slight system anomaly causes an alarm to sound, you'll see a lot of false alarms. You then have the cry-wolf scenario, in which alarms are ignored in emergency situations. If the bounds are set widely enough to avoid false alarms, alarms won't occur as early as you'd like when a parameter slowly drifts out of its desired range. The only solution is to provide nonintrusive monitored information that allows observation of the state of the system over time. Simple changes, such as a monitored temperature that rises slowly after the set temperature has been changed, reflect the proper operation of a furnace.
Values displayed in an analog fashion, such as a bar graph or an analog needle indicator, are quicker to read and better at providing relative measures, especially if minimums and maximums are shown. Digital displays are more precise but require more concentration by the user. Ideally, you should provide both. If average or recent values are available, the user can notice sudden changes in behavior. These changes may be early warning signs of an impending problem.
You must decide how much information to present to the user. Avoid presenting too much information, as that could make important patterns difficult to decipher. When safety is an issue, you should present information from as many independent channels as possible. Consider a furnace with two monitoring thermistors positioned in different parts of the furnace, so the user can monitor how evenly the furnace is heating. The user can look at the average or current temperature on each one.
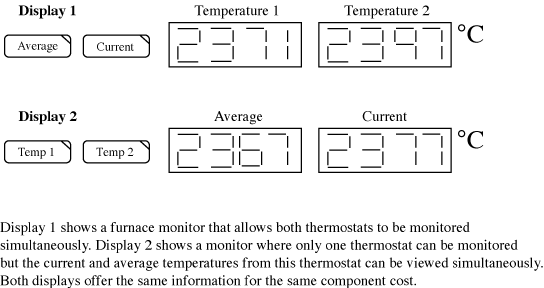
Figure 2. A pair of possible GUI sensor display options.
Figure 2 shows two possible displays for this furnace. Both have the same manufacturing cost because they use the same components. In each case, the thermistor's average or current temperature is displayed. In terms of safety, though, display 1 has a distinct advantage. In display 2, if thermistor 1 fails and its data is unreliable, only information from the faulty sensor is displayed. However, if display 1 is chosen, data from each sensor is always visible. A faulty sensor will be noticed because the values from both sensors will diverge greatly. In any case, if the user monitors all four values regularly, the problem will be noticed. However, with display 2, the user may never bother to switch to the second thermistor. After a few weeks of using a properly functioning system, the user may believe that the variation between the thermistors isn't significant enough to affect normal operation. A user's behavior always adapts to the normal situation, sometimes at a great cost should a fault occur.
You can argue that a simple alarm can check the difference between the two thermistors and annunciate if the difference becomes too large. If the second thermistor is added for redundancy alone and is located in the same part of the furnace, then this system may be feasible. In many control systems, however, separate sensors monitor points that are expected for a number of reasons to be different. Characterizing the differences can be difficult. During warm-up or cool-down, the differences may be larger than those seen during quiescent conditions. If an alarm's tolerance is set wide enough to cover all possible situations, it may be wide enough to allow a faulty sensor to pass its test. This leaves you back at square one, where the user must evaluate the information. Variations between the sensors may make the difference unsuitable as an alarm parameter, but the difference should be checked at some point when the system is stable, as a safety check that the components are functioning correctly.
Alarms
Safety-critical systems require both an alarm system and a monitoring system to provide warnings of device failure and to warn of possibly dangerous patterns in the monitored parameters. If a possibility exists that the user isn't looking directly at the device, you should include an audible alarm. For some classes of device, an audible warning is legally required.
In some cases, the monitor and alarm can be combined as a single display.
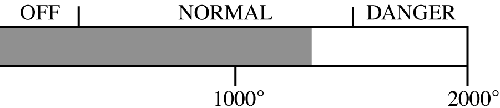
Figure 3. Displaying the alarm threshold allows the user to anticipate an alarm condition.
Figure 3 shows a temperature bar graph labeled to show where the alarm is to be annunciated. Color coding can also be used. This type of display allows the user to anticipate the alarm before it occurs and to take evasive action.
Text lists vs. dedicated annunciators
Video display units (VDUs), whether LCD screens or more bulky cathode ray tube (CRT) screens, allow you to display an alarm as a text message, rather than requiring a dedicated indicator. If the number of possible alarms is high—nuclear power station monitoring rooms have hundreds of possible alarms—then the VDU is the only option because of the amount of space that would be occupied by many individual annunciators. The VDU has an added advantage if secondary information, such as a value for the monitored parameter, can be displayed with the alarm. A VDU can also order the alarms, either chronologically or priority-based. The user can be given several filtering options, such as displaying only temperature-related alarms or alarms that occurred in the last five minutes. Several views of the system can provide the user with extra insight into the cause of the alarms. Sometimes the user tries to identify a real problem that is obscured by many nuisance alarms.
On the other hand, individual annunciators (often LEDs and a label) allow a visible pattern to emerge from the combination of conditions at any given moment. These annunciators are sometimes called tiles because they may form a large area of small squares. No real-estate competition exists between alarms; one alarm never forces another off the screen. The user knows which condition is associated with an indicator and does not have to read a lot of text to establish it.
Text-based alarms on a VDU may cause confusion by giving the user too much information. It's too easy for developers to give a long and informative description of the condition. In an emergency, many conditions are annunciated simultaneously, challenging the user's ability to read all of the generated text. An LCD-based VDU may not be bright enough for an alarm to be noticed from the far side of the room. Sometimes, audible alarms are not directional enough and the user may need to establish the alarm's source by glancing at many devices. This is particularly true in hospital intensive-care units, where each patient can be connected to several devices capable of generating audible alarms.
You can effectively compromise by using bright indicators for the most urgent alarm, and including further information on the VDU. Alternatively, you can use a small number of annunciators for the most important conditions, while the less-frequent or less-urgent conditions can be displayed only on the VDU. Data suggest that individual annunciators outperform a VDU with text only. But VDUs surpass individual annunciators when they make use of color and graphics that allow the user to analyze the data.2
Cry wolf
Having many alarm conditions isn't necessarily better than having just a few. Nuisance alarms may end up being ignored or disabled, which is worse than not having the alarm at all. If the alarm is absent, you have to accept that the parameter simply isn't monitored. If the alarm is present but unreliable, it gives the superficial impression that a dangerous condition will be detected. In practice, users may assume that an alarm is false, like many previous ones, and ignore it.
In some cases, the nuisance alarm did not indicate a failure but was simply specified to a tight criterion. Criteria that seem reasonable on the drawing board aren't always so reasonable when you factor in manufacturing variability, real operating conditions, and years of wear and tear. An alarm sensor can be replaced or fixed if it fails, but if the design limits are wrong, the users may not be able to change them.
You can reduce the number of false alarms in several ways. First, pick reasonable limits for the parameter you are monitoring. This may not be enough, however, as the signal may be noisy. If so, you can filter the signal at several levels. The analog signal can be electronically filtered to dampen some noise, or the software can specify that the alarm must be active for a period of time before the alarm sounds. If the condition is checked on a regular basis, a number of bad readings can be required before declaring the alarm. A four-out-of-five readings rule may work better than a four-in-a-row rule, avoiding the situation in which a genuine alarm condition occasionally spikes into the valid area and prevents the alarm from sounding. Figure 4 illustrates this point.
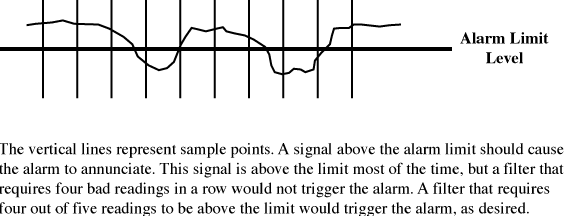
Figure 4. Illustration of alarm sampling.
Some alarms sound only in certain modes of operation. During startup or shutdown, conditions may occur that are not acceptable during normal operation. Stanton (1994) calls these alarms standing alarms . You can avoid standing alarms by widening limits or disabling some alarms during the changeover period. Take care with this approach to ensure that the disabled alarms aren't left disabled after the changeover is finished. It may not be wise to filter out all standing alarms, though. In some cases, users expect alarms in certain phases of operation. They reassure the user that the requested change is actually happening and that the alarm is functioning correctly. If there are few alarms and they do not disguise critical conditions, then allowing the user to observe the alarms may be better than filtering them out completely. For example, a low-pressure alarm may be expected when a pneumatic system is turned on; this alarm would automatically reset once the system has had time to reach the required pressure. This setup would reassure the user that the alarm is working and that the appropriate pressure change has taken place within the system.
Testing alarms
Alarms should be tested regularly during a device's operating life. Testing the alarm system during design can verify that the system is capable of detecting the appropriate alarm conditions. However, it's important that during the life of the product, alarm systems don't become ineffective because of component failure or unexpected environmental conditions. Other system features may be exercised so often that the user is soon aware if they fail. Alarms may get exercised rarely, but they must work when exercised. If alarms aren't tested regularly and they fail silently, the operator may perform dangerous actions but believe them to be safe because no alarm occurred.
Two levels of testing are possible: external and internal. External testing is more reliable, but may not always be a viable option.
With the external method, the condition the alarm is meant to detect is physically created external to the device. For example, you could light a match to generate smoke near a smoke detector. The external method tests the entire system so you can be sure the alarm will function properly when it runs normally.
With the internal method, you can only test certain parts of the alarm system as part of the system's self-test. It is possible that the alarm will appear to work in test mode, but could fail when running normally due to a fault at any point in the alarm system. Take for example a button on a smoke detector that causes the alarm to sound. This test ensures that the battery and speaker are working correctly. However, it wouldn't detect a clogged air inlet. When you start the ignition of a car, the warning-indicator lights on the dashboard illuminate, which tells you that the indicator bulb is working. This test is worthwhile because the bulb is a likely point of failure. However, this test doesn't confirm that the entire warning system works. If the temperature sensor used to detect an overheating engine fails, that failure isn't detected by the lights-on test at ignition.
Although the external method is obviously preferable to ensure reliability, in some cases generating the condition is too hazardous or too expensive for routine testing. You can't overheat a nuclear reactor to establish that the alarm systems are operating, as the hazard would far outweigh the benefit of testing the alarm system. There are also cases in which the designers can't depend on users to take the time to generate alarm conditions. In those cases, internal testing comes into play.
Discovering safety-critical mistakes
Many accidents can be attributed to poor user interfaces. Accidents involving devices in your industry may be well documented. However, such accidents may be rare enough that establishing patterns is difficult, or the information may be heavily censored for liability reasons. In the most unfortunate cases in the aviation industry, the pilot doesn't survive to explain what went wrong. For these reasons, you should gather information on the near misses, especially if you can talk with the user and get a full understanding about what aspect of the interface caused confusion. This excercise is not always a trivial one.
Neumann (1995) compiled descriptions of computer-related mishaps in many safety-critical areas.3 However, you will most likely have to gather your own information on your area of expertise to fully understand the risks for an individual device. More experienced users are often happy to discuss situations that involved less senior and, possibly, less well-trained staff. Your company's service and training functions may have many anecdotes of user mistakes. The biggest drawback with second-hand information is that you can't always find the person who made the mistake to investigate the actions in question.
Imagine you're part of a team that has just begun the development of a safety-critical system. Team members consider it important to discover where errors were common in the interfaces of your product's predecessors, especially if the errors were safety-critical. So you gather a cross-section of the user community and address them: "Please tell me about all the occasions in which you made serious errors using the current equipment. I am particularly interested if your mistakes put peoples' lives in danger."
No matter how nicely you dress up this request, people will be reluctant to reveal mishaps in which they were involved. In some cases, you will need to guarantee that the information will be confidential, especially from their employer. In the United States, the Air Safety Reporting System (Leveson, 1995) provides a confidential means for pilots and others to report on aviation-related incidents in which safety was compromised. Confidentiality is a crucial contributor to the program, which has identified many risks in the aviation industry.
Low cost, big benefits
We've discussed how safety is a system-wide property that must be addressed at the requirements level to ensure that you design the right system. User interface design is an area in which safety improvements can be achieved—often at little cost, but with widespread benefits.
Endnotes
1. Leveson, Nancy. Safeware, System Safety and Computers. Reading, MA: Addison-Wesley, 1995. [back]
2. Stanton, Neville. Human Factors in Alarm Design. London: Taylor & Francis Ltd., 1994. [back]
3. Neumann, Peter G. Computer Related Risks. Reading MA: Addison-Wesley, 1995. [back]