Rethinking basic programming techniques can avoid many of the problems that heap-based memory management poses for embedded real-time system designs.
General-purpose C and C++ programmers are used to taking heap-based memory allocation for granted. Indeed, most textbook techniques and standard libraries heavily rely on the availability of the heap (or free store, as it is alternatively called). However, if you have been in the embedded real-time software business for a while, you probably learned to be wary of malloc and free (or their C++ counterparts new and delete).
Given the constraints on many embedded systems—hard real-time, extended uptime, limited RAM—embedded programmers should have a thorough grasp of memory management alternatives to heap-based allocation. In this article, I'll first review the pitfalls of using heap-based memory management in embedded real-time systems and multithreaded environments, and of dynamic memory allocation in general. Then, I'll present a couple of ways to achieve a fundamental programming technique that typically relies on heap-based memory allocation—polymorphism—without using heap memory.
Heap Problems in Embedded Systems
Embedded real-time systems are particularly intolerant of heap problems for a variety of reasons. First, heap-based allocation is subject to fragmentation. Dynamically allocating and freeing memory can fragment the heap over time to the point that the program crashes because of an inability to allocate more RAM. The total remaining heap storage could be more than adequate, but because of fragmentation there might be no single piece available to satisfy a specific malloc request.
Heap-based memory management is also wasteful. All heap management algorithms must maintain some form of header information for each block allocated. At the very least, this information includes the size of the block. For example, if the header causes a four-byte overhead, then a four-byte allocation requires at least eight bytes, so only 50 percent of the allocated memory is usable to the application.
Because of this overhead and the aforementioned fragmentation, determining the minimum size of the heap is difficult. Even if you were to know the worst-case mix of objects simultaneously allocated on the heap (which you typically don't), the required heap storage is much more than a simple sum of the object sizes. As a result, the only practical way to make the heap more reliable is to massively oversize it.
In addition, heap-based allocation can pose performance issues for real-time systems. Both malloc and free can be (and often are) non-deterministic, meaning that they could take a long time to execute (though "long" here is often hard to quantify). Non-determinism conflicts squarely with real-time constraints. Although many RTOSes (real-time operating systems) have heap management algorithms with bounded, or even deterministic, performance, they don't necessarily handle multiple small allocations efficiently.
Heap Problems in Multithreaded Environments
Unfortunately, the list of heap problems doesn't stop there. A new class of problems appears when you use heap in a multithreaded environment. Here, the heap becomes a shared resource and consequently causes all the headaches associated with resource sharing, so the list goes on.
Both malloc and free can be (and often are) non-reentrant; that is, they cannot be safely called simultaneously from multiple threads of execution. This reentrancy problem can be remedied by protecting malloc, free, realloc, and so on internally with a mutex semaphore, which lets only one thread at a time access the shared heap (for instance, the VxWorks RTOS from Wind River Systems does this). However, this scheme could cause excessive blocking of threads (especially if memory management is non-deterministic) and can significantly reduce parallelism.
Mutexes are also subject to priority inversion.1 Naturally, the heap management functions protected by a mutex are not available to ISRs (interrupt service routines) because ISRs cannot block.
Other Pitfalls of Dynamic Memory Allocation
Finally, all the problems listed previously are in addition to the usual pitfalls associated with dynamic memory allocation. For completeness, I'll mention them here as well.
If you destroy all pointers to an object and fail to free it, or you simply leave objects lying about well past their useful lifetimes, you create a memory leak. If you leak enough memory, your storage allocation eventually fails.
Conversely, if you free a heap object but the rest of the program still believes that pointers to the object remain valid, you have created dangling pointers. If you dereference such a dangling pointer to access the recycled object (which by that time might be already allocated to somebody else), your application can crash.
Most heap-related problems are notoriously difficult to test. For example, a brief bout of testing often fails to uncover a storage leak that kills a program after a few hours, or weeks, of operation. Similarly, exceeding a real-time deadline because of non-determinism can show up only when the heap reaches a certain fragmentation pattern. These types of problems are extremely difficult to reproduce.
This is quite a litany, although I didn't even touch the more subtle problems yet; for example, an exception-handling mechanism can cause memory leaks when a thrown exception "bypasses" memory de-allocation. (Here is an idea: why don't you use this list when interviewing for an embedded systems programmer position? Awareness of heap problems is like a litmus test for a good embedded systems programmer.)
Mitigating Problems of Heap Memory
So why use the heap at all? Well, because the heap is so convenient, especially in general-purpose computing. Dynamic memory management perfectly addresses the general problem of not knowing how much memory you'll need in advance. (That's why it's called general-purpose computing.)
If you go down this list again, you will notice that most of the heap problems are much less severe in the desktop environment than they are in embedded applications. For a desktop application, with only "soft" real-time requirements, all issues (except dangling pointers, perhaps) boil down to inefficiencies in RAM and CPU use.
The obvious technique that cures many issues is to massively oversize the heap. To this end, all desktop operating systems these days support virtual memory, which is a mechanism that effects a manifold increase in the size of available RAM by spilling less frequently used sections of RAM onto disk.
Another interesting approach, brought to the forefront by Java (not that it wasn't known before), is automatic garbage collection. You can view garbage collection as a software mechanism to simulate an infinite heap. It addresses the problems of dangling pointers, storage leaks, and heap fragmentation (albeit at a hefty performance price tag). Unfortunately, the other issues, especially deterministic execution, remain unsolved and are actually aggravated in the presence of garbage collection.
For decades, heap problems have been addressed in desktop environments with ever more powerful hardware. Fast CPUs, cheap dynamic RAM, and massive virtual memory disk buffers can mask heap-management inefficiencies and tolerate memory-hungry applications (some of them leaking like a sieve) long enough to allow them to finish their job. (That's why it's a good idea to reboot your PC every once in awhile.)2
Not so in the embedded real-time business! Most embedded systems must run for weeks, months, or years without rebooting, not to mention the small amount of RAM they typically must get by with. Under these circumstances, the numerous problems caused by heap-based memory allocation can easily outweigh the benefits. You should very seriously consider not using the heap, especially in smaller embedded designs.
Even though the free store is definitely not a "free lunch," getting by without it is certainly easier said than done. In C, you will have to rethink implementations that use linked lists, trees, and other dynamic data structures. You'll also have to severely limit your choice of the third-party libraries and legacy code you want to reuse (especially if you borrow code designed for the desktop). In C++, the implications are even more serious because the object-oriented nature of C++ applications results in much more intensive dynamic-memory use than in applications using procedural techniques. For example, a lack of dynamic storage implies that you will lose many benefits of constructors, because you'll often be forced to instantiate objects at times when you don't have enough initialization information.
Polymorphism without a Heap
However, perhaps the biggest problem is that heap-based memory allocation is at the heart of so many basic programming techniques, and that most programmers are trained to use them without giving it a second thought. Consider, for example, one of the most typical (textbook) use cases of polymorphism.
Suppose you were to develop a C++ program for a $9.99 "MySongMaker" toy keyboard (such as my six-year-old daughter uses to torture the family from time to time). "MySongMaker" can imitate many instruments such as the piano, violin, organ, etc., which are selectable at run time by a button press.
Figure 1(a) shows a standard design with an Instrument base class defining an abstract operation playNote that concrete subclasses (such as Piano) override.
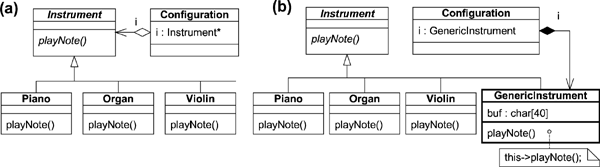
Figure 1. (a) Standard heap-based design for "MySongMaker" keyboard and (b) a solution without the heap
In this design, selecting the instrument corresponds to instantiating the concrete Instrument subclass, and playing the instrument boils down to invoking the virtual playNote function for every note (key press). The standard (heap-based) way of coding the design would look approximately as follows:
Instrument *i; . . . i = new Piano; // select instrument Piano . . . i->playNote(key); // play a note . . .
Obviously, this snippet of code is very incomplete. At the very least, you must delete the previous instrument before reassigning the pointer i, and you must explicitly handle the situation when new fails. (How do you explain to a kid that her keyboard broke because it ran out of heap?) But this is not all. Things get more complicated if you need to store the current instrument as part of another object. (Indeed, "MySongMaker" can record simple "compositions" and thus must store the configuration.)
In the standard design, you'd invent a class Configuration, which would contain a pointer (or reference) to the Instrument class, as shown in Figure 1(a). Since the Configuration class contains a pointer, the standard rule requires providing a destructor, overloading the assignment operator, and defining the appropriate copy constructor. Although the code for these elements isn't terribly complicated, the overall price for this little bit of polymorphism seems high. However, perhaps the most disturbing aspect of this traditional design is that once you start using the heap you are stuck for good and you need to keep churning the heap forever (e.g., inside the assignment operator and the copy constructor). Nevertheless, you probably employ such designs every day without thinking twice, because that's the standard way of implementing polymorphism on the desktop.
1: typedef char Note;
2:
3: class Instrument
4: {
5: public:
6: virtual void playNote(Note key) = 0;
7: };
8:
9: class GenericInstrument : public Instrument
10: {
11: char buf[40]; // maximum size of an Instrument
12: public:
13: virtual void playNote(Note key)
14: {
15: this->playNote(key); // enforce late binding
16: }
17: };
18:
19: class Configuration
20: {
21: public:
22: //...
23: GenericInstrument i;
24: //...
25: };
Listing 1. instrument.h - Declaring abstract class Instrument, GenericInstrument subclass, and Configuration class
An embedded developer, however, would probably think twice before accepting such a design. Figure 1(b) shows an example of a solution that doesn't require the heap. As you can see, the Configuration class in this design aggregates by composition the whole instance of a GenericInstrument subclass of Instrument, instead of the Instrument pointer, as in the traditional design. The GenericInstrument class is never intended to be used as such, but rather just to hold an instance of any other Instrument subclass (such as Piano or Violin). Obviously, GenericInstrument must be big enough, which you can achieve by appropriately sizing its attribute buf[] (see Listing 1, line 11). While a desktop programmer would probably frown at such hard coding of the upper size limit for all (perhaps unknown yet) subclasses of Instrument, this is a perfectly reasonable thing to do for an embedded programmer. You see, an embedded developer is used to budgeting memory anyway, and the size of GenericInstrument provides just this: the worst-case size of any Instrument subclass.
1: #include "instrument.h"
2: #include <new.h> // for placement new
3: #include <iostream.h>
4: #include <assert.h>
5:
6: class Piano : public Instrument
7: {
8: int attr; // an attribute
9: public:
10: Piano()
11: {
12: assert(sizeof(*this) <= sizeof(GenericInstrument));
13: }
14: virtual void playNote(Note key);
15: };
16:
17: class Violin : public Instrument
18: {
19: int attr1; // an attribute
20: int attr2; // another attribute
21: public:
22: Violin()
23: {
24: assert(sizeof(*this) <= sizeof(GenericInstrument));
25: }
26: virtual void playNote(Note key);
27: };
28:
29: void Piano::playNote(Note key)
30: {
31: cout << "Piano " << key << endl;
32: }
33:
34: void Violin::playNote(Note key)
35: {
36: cout << "Violin " << key << endl;
37: }
38:
39: static Configuration c1, c2;
40:
41: int main()
42: {
43: new(&c1.i) Piano; // instantiate Piano
44: c1.i.playNote('c');
45: memcpy(&c2, &c1, sizeof(Configuration));
46: static_cast<Instrument *>(&c2.i)->playNote('d');
47:
48: new(&c1.i) Violin; // instantiate Violin
49: c1.i.playNote('e');
50: c1 = c2; // Oops, doesn't copy the v-pointer!
51: c1.i.playNote('f');
52:
53: return 0;
54: }
Listing 2. Test case for GenericInstrument and Configuration classes
However, it is always a good idea to assert that the concrete subclass of Instrument (such as Piano or Violin) would indeed fit (see Listing 2, lines 12 and 24). Listing 2 also demonstrates how you can instantiate an arbitrary subclass of Instrument inside a GenericInstrument object by using placement new (lines 43 and 48). Please note that you need to include the <new.h> header file in order to use placement new.
Another point of interest in this design is arranging for late binding while invoking virtual method(s) defined in the Instrument superclass, such as playNote. Because now we use an instance of the GenericInstrument class (rather than a pointer to the Instrument class, as in the standard design), a C++ compiler would synthesize a regular (early binding) call. One way of enforcing the late binding would be to replace every such call (say, i.playNote) with a call via a pointer, which then needs to be explicitly upcast to Instrument*, as demonstrated in line 46 of Listing 2. However, such an approach is ugly and requires clients to remember which methods are virtual (and require late binding) and which are not.
A better way is to inline a pointer-based call inside the GenericInstrument class, as shown in Listing 1, line 15. At first, the GenericInstrument::playNote implementation might look like a classic example of endless recursion. However, as stated earlier, the GenericInstrument subclass should never hold an instance of itself (in other words, its virtual pointer will never point to GenericInstrument's virtual table), so the call always resolves through a virtual table of some other Instrument subclass. GenericInstrument::playNote is defined inline, so the indirect virtual call via this method should be optimized away.
Finally, I would like to point out a potential pitfall of this approach. You might have noticed that in line 45 of Listing 2 the Configuration object is copied byte-for-byte using memcpy, rather than the assignment operator, as in line 50. The reason for avoiding the default assignment operator is that it does not copy the virtual pointer. (So in spite that c2.i is always a Piano, the method invoked in line 51 is Violin::playNote.) Obviously, you could remedy the problem by explicitly overloading the assignment operator in class GenericInstrument, for instance, as follows:
GenericInstrument & operator=(const GenericInstrument &x)
{
if (&x != this)
memcpy(this, &x, sizeof(*this));
return *this;
}
I hope you find this little technique useful, or at least thought-provoking. However, I don't want to pretend that the design fits well within the C++ fabric. In fact, it must fight the C++ compiler in too many places, because polymorphism in C++ seems to be really designed with heap-allocated objects in mind. And this is exactly the problem I wanted to illustrate: using C or especially C++ in an embedded domain requires sometimes going off the beaten path, because the vast majority of the coding techniques have been designed for programming general-purpose computers.
Another Approach to Non-Heap Polymorphism
Fortunately, this technique of changing an object's class at run time without using the heap is just one way of skinning the cat. Listings 3 and 4 present an improved design, for which I'd like to thank Jeff Claar.
typedef char Note;
class Instrument {
public:
virtual ~Instrument() {}
virtual void playNote(Note note) = 0;
};
enum { MAX_INSTRUMENT_SIZE = 40 };
class GenericInstrument {
char buf[MAX_INSTRUMENT_SIZE];
public:
Instrument *operator->() {
return (Instrument *)buf;
}
Instrument const *operator->() const {
return (Instrument const *)buf;
}
Instrument *get() { // For placement new or delete
return (Instrument *)buf;
}
};
class Configuration {
public:
//...
GenericInstrument i;
//...
};
Listing 3. instrument2.h - Improved declarations for abstract class Instrument, GenericInstrument subclass, and Configuration class
#include "instrument2.h"
#include <new.h> // for placement new
#include <iostream.h>
#include <assert.h>
class Piano : public Instrument {
int attr; // an attribute
public:
Piano() {
assert(sizeof(*this) <= MAX_INSTRUMENT_SIZE);
}
virtual void playNote(Note key);
};
class Violin : public Instrument {
int attr1; // an attribute
int attr2; // another attribute
public:
Violin() {
assert(sizeof(*this) <= MAX_INSTRUMENT_SIZE);
}
virtual void playNote(Note key);
};
void Piano::playNote(Note key) {
cout << "Piano " << key << endl;
}
void Violin::playNote(Note key) {
cout << "Violin " << key << endl;
}
static Configuration c1, c2;
int main() {
new(c1.i.get()) Piano; // instantiate Piano
c1.i->playNote('c');
c2 = c1;
c2.i->playNote('d');
new(c1.i.get()) Violin; // instantiate Violin
c1.i->playNote('e');
c1 = c2;
c1.i->playNote('f');
return 0;
}
Listing 4. Test case for improved classes
Jeff's method replaces inheritance with object composition, so GenericInstrument does not inherit from Instrument, but rather contains a concrete Instrument subclass. Further, overloading the operator-> in GenericInstrument enables convenient and intuitive access to virtual functions of the Instrument superclass.
Jeff's technique is more elegant, better optimized, and seems to blend much better with C++. My investigation of the machine-code output from various C++ compilers shows that Jeff's design doesn't incur any overheads either in virtual method invocation (assuming that the operator-> is inlined) or in memory usage. In contrast, my technique always leads to generation of an unused virtual table for the GenericInstrument class.
Both of these methods illustrate that embedded systems don't need to abandon such powerful techniques as polymorphism. The main point is that you usually can find a suitable workaround, but this requires an embedded-system-specific attitude to programming—what I call the "embedded mindset."
Endnotes
1. Every time you call malloc (or new), you might be running the risk of priority inversion, that is the deadly condition in which a low-priority thread blocks a ready and willing high-priority thread indefinitely. Priority inversion can be a show stopper in any real-time system; yet, most less sophisticated RTOSes don't support any mechanisms to prevent it. Even the high-end systems, which can detect and remedy the condition (by applying priority-inheritance or priority-ceiling protocols), don't enable these mechanisms by default because of the high overhead involved. A highly-publicized example of a system failure caused by priority inversion is the Mars Pathfinder mission in July 1997. The mission (eventually very successful) was saved by remotely enabling priority inheritance in the VxWorks mutex implementation that was originally not activated because of its high overhead (e.g., see "Priority Inversion: How We Found It, How We Fixed It"). [back]
2. Once upon a time, computer memory was one of the most expensive commodities on earth, and large amounts of human ingenuity were spent to invent memory-efficient programming techniques. These days, the developers who know how to write memory-efficient code are rapidly becoming an endangered species. However, as James Noble and Charles Weir point out in their book Small Memory Software: Patterns for Systems with Limited Memory (Addison-Wesley, 2000), a more thoughtful usage of memory has many unexpected benefits that go far beyond the dollar cost of RAM chips. Although aimed at a general-purpose programmer, this book is especially relevant to an embedded developer. [back]