Major semiconductor manufacturers are starting to sell a new type of integrated circuit, the network processor. Network processors are programmable chips like general purpose microprocessors, but are optimized for the packet processing required in network devices. But what are they good for and how do they work?
Network devices are a growing class of embedded system and include traditional Internet equipment like routers, switches, and firewalls; newer devices like Voice over IP (VoIP) bridges, virtual private network (VPN) gateways, and quality of service (QOS) enforcers; and web-specific devices like caching engines, load balancers, and SSL accelerators.
In this article, I will describe the processing requirements of network devices, how traditional designs meet those requirements, how network processors aim to meet those requirements, and the architecture of a few network processors in detail.
Network processing requirements
Part 1
Not all network devices have the same processing requirements. However, a lot of similarities exist. As an example, I will roughly describe the packet processing duties of a router and a web switch. These core, time-critical duties are also called data plane tasks.
Routers are the workhorses of the Internet. A router accepts packets from one of several network interfaces, and either drops them or sends them out through one or more of its other interfaces. Packets may traverse a dozen or more routers as they make their way across the Internet. Here is a simplified version of the IP routing algorithm:
- Remove the link layer header
- Find the destination IP address in the IP header
- Do a table lookup to determine the IP address of the next hop
- Determine link layer address of the next hop
- Add link layer header to packet
- Queue packet for sending
- Send or drop packet (if link is congested)
Web switches, by contrast, are a new type of network device. They address the problem of trying to increase the responsiveness of a popular Web site by using more than one web server. A web switch can direct incoming HTTP requests to different servers based on a variety of networking parameters, including the URL itself. For instance, all secure HTTP requests could be forwarded to a special web server with cryptographic hardware to accelerate those requests. Here is a simplified web switch algorithm:
- Accept incoming TCP connection (three-way handshake)
- Buffer incoming TCP data stream (TCP/IP protocol)
- Parse the stream to find the URL being requested
- Do a table lookup to determine where to forward the request
- Open TCP connection with web server (three-way handshake)
- Send buffered request (TCP/IP protocol)
Note that, for a given bandwidth, the web switch processing requirements are much higher, and require much more state than the router processing requirements. The difference arises because a router processes packets, but a web switch processes connections.
Part 2
The previous description of the core operations of a router and a web switch were not complete. A major piece was missing. What was it? Device management. How do you configure and control this device?
A variety of less time-critical tasks fall outside the core processing or forwarding requirements of a network device. These are called control plane tasks. For a router, these tasks include routing protocols like OSPF and BGP, and management interfaces like serial ports, telnet, and SNMP. For a web switch, these tasks include receiving updates about the status of web servers and providing a web interface for configuration and management. For both devices, error handling and logging are important control plane tasks.
Another way to distinguish data plane tasks from control plane tasks is to look at each packet's path. Packets handled by data plane tasks usually travel through the device, while packets handled by control plane tasks usually originate or terminate at the device.
Data plane vs. control plane
Network engineers have noticed an interesting relationship between data plane tasks and control plane tasks. Data plane tasks require a small amount of code, but a large amount of processing power. In contrast, control plane tasks require little processing power, but a large amount of code.
Using a router as an example, this phenomenon can be considered from two vantages, code size or processing requirements. The data plane tasks of a router were described briefly in the previous section, and a detailed description would not be much longer. It seems apparent that one could handle the data plane tasks without a lot of code.
The control plane tasks were also described, but the description was not nearly as precise. Even in a traditional network device like a router, control task implementations vary. All routers will have code to handle routing protocols like OSPF and BGP, and they will almost certainly have a serial port for configuration. But they may be managed via a web browser, Java application, SNMP, or all three. This can add up to a lot of code. If you're still not convinced, look at the size of Cisco's books on how to configure its routers.
Now, let's consider the packets entering the router. Nearly all of them are addressed to somewhere else, and need to be examined and forwarded there very quickly. For example, for a router to run wire-speed with a 155Mbps OC-3 link, it needs to forward a 64-byte packet in three microseconds. These packets may not need to have much done with them, but it needs to be done in a timely manner.
This requires tight code and a lot of processing power. By contrast, the occasional OSPF packet that causes the routing tables to be updated, or an HTTP request to make a configuration change might require a fair bit of code to be handled properly, but will have little impact on overall processing requirements.
Fast path, slow path
The different requirements of data plane and control plane tasks are often addressed by what is called a fast path-slow path design. In this type of design, as packets enter the networking device, their destination address and port are examined, and based on that examination, they are sent on either the "slow path" or the "fast path" internally. Packets that need minimal or normal processing take the fast path, and packets that need unusual or complex processing take the slow path. Fast path packets correspond to data plane tasks, while slow path packets correspond to control plane tasks. Once they have been processed, packets from both the slow and fast path may leave via the same network interface. See Figure 1.
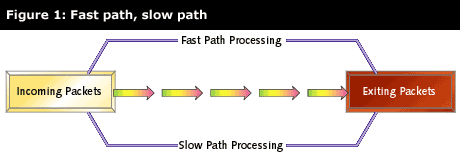
Dividing up the processing in this way provides substantial implementation flexibility. While the slow path processing will almost certainly be implemented with a CPU, fast path processing can be implemented with an FPGA, ASIC, co-processor, or maybe just another CPU. This architecture is particularly strong because it allows you to implement simple time-critical algorithms in hardware and complex algorithms in software.
Now that we have a handle on network processing requirements, let's start looking at network processors.
ASICs
Over the last 10 years, demand for higher bandwidth networks has driven the evolution of network equipment design. The first designs used CPUs exclusively. However, general purpose CPUs are not ideal for network programming. While their programmability is important, their floating-point units go unused, they have too much data cache, and too little memory bandwidth. Further, demand for bandwidth is increasing faster than CPU speeds. Network equipment designers cannot afford to wait for the next generation of CPUs to increase the speed of their devices. Even with fast path-slow path designs, problems still arise. For example, how do you make the fast path fast enough?
The conventional answer is to design an ASIC. Well-designed ASICs can be much faster than CPUs, but they are difficult and expensive to develop; the cost of the tools alone make them unaffordable for many companies. Moreover, ASICs usually have limited programmability and must be redesigned as protocols and interfaces change. Network processor companies hope to bridge the divide between ASICs and CPUs by providing a device that is as programmable as a CPU but as fast as an ASIC.
Network processor architectures
Network processor architectures make CPU architectures look staid and boring. Network processor designers from different companies have made vastly different decisions about I/O interfaces, memory interfaces, and programming models, not to mention system architecture and what flavors of hardware acceleration to include.
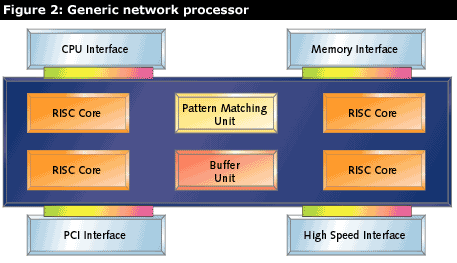
Figure 2 is a block diagram of a generic network processor. It does not represent a specific network processor, but includes traits common to most. These traits are:
- Multiple RISC cores
- Dedicated hardware for common networking operations
- High-speed memory interface(s)
- High-speed I/O interfaces
- Interface to general purpose CPU
Programming a network processor
Since network processors are very different from general purpose processors, the most important question for programmers is, how do you program it? How do you make effective use of multiple RISC cores and hardware acceleration units? Every network processor vendor insists that their design is the easiest to program, so it is good to think critically about this question.
In many ways, network processor architectures look like the parallel processing architectures of a decade ago. Programmers have tried to harness the power of parallel processing architectures for a long time, but with little luck. Vector-processing supercomputers are used for special purpose applications like weather simulation, but programmers have not been successful in using them for general purpose applications.
Is there any reason to think network processors will fare better? Yes, there is. Network processors are not trying to speed up general purpose processing. Network processing has certain characteristics that are very different from general purpose processing. Network processing involves less code but more data than general purpose processing. There is less interdependency between the data. Consider a router again. If a router receives n packets, for a small number n, it can process those packets independently. Another way of saying this is that processing these packets doesn't change the router's state. The exception to this would be configuration packets, or routing protocol packets. However, even these interdependencies are rather loose. If a router receives a packet that indicates it should update its routing tables, there is no reason it can't finish processing a few more packets before it does the update.
Interpacket dependencies
On the other hand, for the web switch there are substantial interpacket dependencies. A large class of packets must be processed in the order they are received. The web switch must maintain the semantics of a TCP connection, which means it must buffer packets it has received until it has received enough to parse out the URL. When forwarding the request to a web server, the web switch must save packets that it has sent but have not yet been acknowledged, in case they need to be resent. Despite these interdependencies, a web switch can still benefit from parallelism. How? If the packets are sorted so that packets for a particular connection always go to the same RISC core, then packets for that connection will be processed in order, and interpacket dependencies will have been observed.
If you are evaluating a network processor, you should carefully consider what kind of interpacket dependencies you have, and how each network processor handles them. Network processors designed for very high speed traffic often have no provision for interpacket dependencies and thus would not be appropriate for network devices doing application-level processing.
Speeds and feeds
As indicated above, a wide variety of network processor designs exist. One reason for this is that the interface speeds for network devices range over several orders of magnitude. Table 1 lists the maximum processing time a network device may use if it wants to perform at wire-speed for various interfaces. The rightmost column can be considered a per-packet time budget.
WAN link | Data rate (Mbps) | Maximum processing time (ns) |
T-1 | 1.5 | 340,000 |
T-3 | 45 | 11,000 |
OC-3 | 155 | 3,000 |
OC-12 | 622 | 820 |
OC-48 | 2,500 | 200 |
OC-192 | 9,500 | 51 |
Table 1. Maximum processing time
From reading the marketing literature of network processor vendors, you might believe that all network processors are designed for gigabit speeds, and the faster the better. However, depending on your application, a slower network processor might be a better choice. Network processors designed for the fastest speeds are much more I/O driven, and have less capabilities for pattern matching, sorting out interpacket dependencies, and other features desirable for application-level processing.
Multiprocessing and multithreading
Many network processors include multiple processor cores that run in parallel. Some of the cores, notably those in Intel's IXP1200 and Sitera's Prism network processors, include hardware support for multiple contexts, which essentially results in zero context-switch time between threads on the same core.
For multi-core network processors and multi-threaded cores, an important question is: who handles scheduling? Consider Figure 3, where six packets are destined for our four-core network processors.

Which packet will be processed by which core? In some network processors, this is determined by the hardware. In others, the software determines the answer. Depending on your application and algorithms, the ability to control which packets go to which cores may be an important requirement. For others, the speed of hardware scheduling may be essential.
Market developments
The hot news in the network processor market has been acquisitions and standards. Between September 1999 and June 2000, major semiconductor manufacturers went on a buying spree, each acquiring a network processor or acceleration company. During that time, Intel acquired NetBoost, Conexant acquired Maker, Lucent acquired Agere, Motorola acquired C-Port, and Vitesse acquired Sitera.
On the standards front, companies in the switch fabric and network processor business have formed two standards bodies. The Common Switch Interface Consortium (CSIX) was formed to standardize a hardware interface between switch fabric chips and processing chips.
The Common Programming Interface Forum (CPIX) was formed to standardize software interfaces for network processors. These two groups include in their membership almost every company that has anything to do with network processing, except Intel.
In particular, the aims of CPIX are interesting: develop software standards for network processors, so that network processor software is portable to different network processors. While this would be beneficial to many network equipment manufacturers, vastly different network processor architectures make that prospect unlikely, at least without large performance sacrifices. Until CPIX releases its standard, it looks more like an anti-Intel coalition than a standards body.
Network processor descriptions
C-5 Digital Communications Processor
The C-5 Digital Communications Processor (DCP), shown in Figure 4, may be the most powerful network processor of the bunch. It consists of 16 channel processors (CPs) and five co-processors, all connected through a 50Gbps bus. The channel processors, each of which consist of a 32-bit RISC core and two serial data processors (SDPs), are the heart of the unit. The SDPs are microcode-programmable to implement link layer interfaces including Ethernet, SONET, and serial data streams. Since each RISC core can run a different program, and the channel processors share a common bus, you have a lot of flexibility in distributing your processing across this chip. You could have a parallel processing arrangement where you ran identical programs on several CPs, or a pipelined arrangement where each processor was dedicated to a particular task and passed its output to the input of the next processor. The five co-processors are an executive processor, a fabric processor, a table lookup unit, a queue management unit, and a buffer management unit.
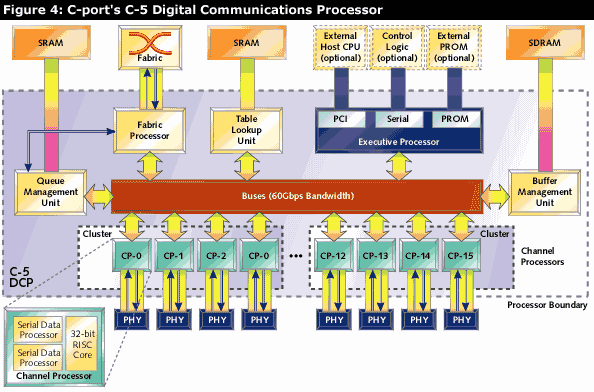
The C-5 DCP has enough processing power to implement both data and control plane operations itself, or it can communicate with a host CPU across a PCI bus interface.
Programming the C-5 DCP is not a small task. With the possibility of writing up to 16 different C/C++ programs for 16 processors, as well as writing microcode for the serial data processors(s), and system level code to tie everything together, a lot of effort goes into harnessing the C-5's power. C-Port's core development tools are based on the popular GNU gcc compiler and gdb debugger, modified by C-Port to work with their RISC cores. To program the RISC cores, you write from one to 16 different programs in C or C++. Then you can debug all of your programs at once using the included C-5 DCP simulator, or you can load your programs on to the C-5 DCP itself, and use gdb to debug them one CPU at a time. C-Port rounds out their development toolset with a traffic generator and performance analyzer.
C-Port provides library routines, named C-Ware, to maintain software compatibility for future generations of DCPs. These routines cover features of both the RISC cores and the co-processors, including tables, queues, buffers, protocols, switch fabrics, kernel services, and diagnostics. The C-Ware reference library includes C-5 implementations of a gigabit ethernet switch, packet over SONET (POS) switch, and ATM switch.
Intel IXP1200
Intel has become a leader in marketing network processors as part of their Internet Exchange Architecture. Currently, most network processor companies are extremely secretive about their products. Intel is the exception. Of the four network processors described in this article, Intel's IXP1200 is the only one for which you can directly download a datasheet from the Web.
The IXP1200, shown in Figure 5, consists of a StrongARM processor, six RISC micro-engines, and interfaces to SRAM/SDRAM memory, PCI bus, and Intel's proprietary IX Bus. The IXP1200 has been designed to do fast path and slow path processing in one chip. The StrongARM portion of the processor can be programmed for the slow path with conventional C/C++ tools. The six micro-engines are designed for fast path processing. Each micro-engine has four hardware contexts and can context switch in a single instruction. The micro-engines are limited to 4KB of program space, which is actually quite a bit, since they are programmed in microcode.
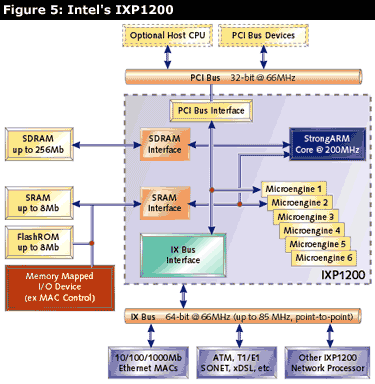
Intel provides assembly tools for the microcode as well as a simulator for debugging the non-StrongARM parts of the IXP1200. Intel ships the IXP1200 development environment with example code for Layer 2 and Layer 3 bridging and routing.
Lucent
Lucent's network processor design is very different from the other three network processors described in this article. It is a three-chip solution for the fast path. System designers need to add a general-purpose microprocessor for slow path processing. Lucent's network processor has three parts: the functional pattern processor (FPP), the routing switch processor (RSP) and the Agere system interface (ASI). Both the FPP and RSP are programmed with 4GLs (fourth-generation languages). See Figure 6.
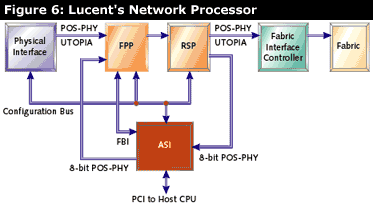
The idea behind the FPP is that there is a large class of network processing functions that require some sort of pattern matching. This includes parsing packets and searching through routing tables. The RSP handles all actions for a particular packet, including packet modifications like routing, and traffic management functions like queueing. The ASI is for sending and receiving slow path packets from a general purpose CPU.
Development kits are available that implement the Lucent network processor using five Xilinx Virtex FPGAs. Clocked at 33MHz, they support full duplex OC-12 interfaces. The tools are not the standard C/C++ development environment that is common with other network processors. The development kit contains:
- Functional programming language compiler-for programming the FPP
- Agere Scripting Language (ASL) Compiler-for programming RSP and ASI
- Java-based simulation environment
- Command-line simulators for the FPP and RSP
- Traffic generator
The Application Code Library includes IP switching and routing over ATM AAL5, over Ethernet, and over Frame Relay.
Sitera
Sitera's network processor family, the Prism IQ2000 (shown in Figure 7), consists of four RISC cores, co-processors for lookup, order management, multi-cast support, DMA management, context management, and interfaces to both SRAM/RDRAM and a general-purpose CPU. Sitera expects the Prism to handle fast path processing and for a CPU to be designed in for slow path processing.
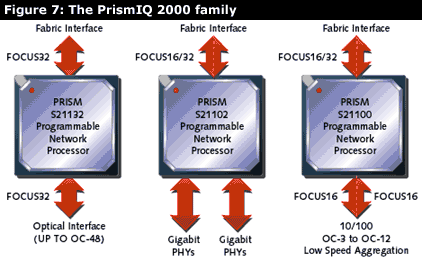
The Prism's RISC cores have a modified version of the MIPS instruction set with four hardware contexts. Packet scheduling is handled in hardware, with the order management co-processor responsible for resolving packet interdependencies. Sitera offers three variations of the Prism IQ2000, each with the same core but different network interfaces. Sitera's Developer's Workbench is based on the GNU C/C++ compiler, but also includes a simulator and traffic generator. Their reference application code supports Layer 2 and Layer 3 bridging and routing.
Conclusions
The network processor industry is at an early stage. Most network processors have only recently started shipping production quantities, and only a few shipping products use network processors. Nevertheless, for developers of networking devices, network processors might be the fastest platform for the next-generation product.
This article was published in the November 2000 issue of Embedded Systems Programming. If you wish to cite the article in your own work, you may find the following MLA-style information helpful:
Kohler, Mark. "NP Complete," Embedded Systems Programming, November 2000, pp. 45-60.