New standards are making the delivery of Web-based and enhanced content alongside television a reality. This article describes the ATVEF enhanced television standard and the requirements for designing ATVEF-compatible receivers.
Despite its failings, the 1996 release of WebTV was the start of a revolution in web surfing. For the first time, connecting to the Internet was as easy as using a television set and an infrared keyboard. WebTV's first Internet set-top product allowed users to surf the web on their television screen, getting email and reading news from their sofas and armchairs. Two years later, their WebTV Plus product improved on this paradigm, allowing users to simultaneously view web content and TV show, with the broadcast signal embedded in the web content, in a picture-in-picture window.
The convergence of computers and televisions has been predicted by technology analysts for many years. Instead of having both PCs and televisions, they suggest we will eventually own only a single device that will have the widespread availability and ease-of-use of television combined with the interactive power and flexibility of a PC. Along this path, we are seeing both devices adopting features formerly reserved for the other.
From the PC side, computers are becoming more adept at handling video content. MPEG compression standards have allowed computers to display video; multicast IP and push technologies allow the TCP/IP protocols to simulate a broadcast infrastructure.
From the TV side, we are just starting to see the emergence of standards that allow web-based content to be broadcast to your television. One of the most popular of these standards is the Advanced Television Enhancement Forum (ATVEF), a non-proprietary specification developed and supported by some of the biggest names in the broadcasting, computer, and consumer electronics industries.
The goal of this article is to discuss the future of television as an "Internet appliance." Because ATVEF is one of the leading standards in the enhanced television world, it seems a good choice to use as an example of where Internet-enhanced TV technology is going. The bulk of this article will be geared towards describing the ATVEF standard and its technical implementation. For the sake of completeness, we will also discuss how ATVEF might be used in the coming years, its industry support, and its major competitors.
Content specification
In a nutshell, ATVEF is a standard for creating enhanced, interactive television content and delivering that content to a range of television, set-top, and PC-based receivers. ATVEF defines the standards used to create enhanced content that can be delivered over a variety of mediums - including analog (NTSC) and digital (ATSC) television broadcasts - and a variety of networks, including terrestrial broadcast, cable, and satellite.
By defining the standards used to create enhanced content, the ATVEF specification also defines the minimum functionality required by ATVEF receivers to parse and display this content. One of the major goals of ATVEF was to create a specification that relies on existing and prevalent standards, so as to minimize the creation of new specifications. Not surprisingly, the group chose to base their content specification around existing Internet technologies such as HTML and Javascript.
Besides minimizing the number of standards that the ATVEF working group needed to create, forcing content creators to base their content on existing Internet technologies provides two other important benefits. First, because the content specifications are fully web compatible, there already exist millions of pages of potential content. And second, considering how easy it is to use many of today's web-authoring tools, practically anyone can become an ATVEF content developer.
The ATVEF 1.0 Content Specification mandates that receivers support HTML 4.0, JavaScript 1.1, and Cascading Style Sheets. This is a minimum content specification because all receivers must support these standards, but they are allowed to support others as well-Java and VRML, for example. Establishing a minimum content specification is important to content developers who want to produce the richest content possible, while ensuring that their content is available to the maximum number of viewers.
With ATVEF's membership being much heavier on the side of content developers than on manufacturers, it is no surprise that the minimum standard provides for nearly the same feature set as the latest PC-based web browsers. However, as more manufacturers consider adopting ATVEF, we are likely to see additional content specifications --perhaps an "ATVEF Lite"- that provides less functionality at a reduced hardware and software cost. This is sure to please companies that design embedded web-browsers, as the majority of embedded browsers don't yet have the same level of content support as typical PC-based browsers.
Of course, including a web browser on a television set introduces some possibilities for exciting new content. To support these, the ATVEF specification calls for new extensions to the existing standards. The most prominent extension to HTML defined by the ATVEF specification is the addition of a "tv:" attribute. The "tv:" attribute specifies the insertion of the television broadcast signal into the content, and may be used in an HTML document anywhere that a standard image may be placed. Creating an enhanced content page that displays the current television channel in one corner of the page is as easy as inserting an image in an HTML document.
In addition to defining what ATVEF content looks like, the specification also defines how that content gets from the broadcaster to the receiver and how the receiver is informed that it has enhancements available for the user to access. The latter task is accomplished with triggers.
Triggers
Triggers are mechanisms used to alert receivers to incoming content enhancements. Triggers are sent over the broadcast medium, and contain information about enhancements that are available to the user. Among other information, every trigger contains a standard Universal Resource Locator (URL) that defines the location of the enhanced content. ATVEF content may be located locally -- perhaps delivered over the broadcast network and cached to a disk -- or it may reside on the Internet, another public network, or perhaps a private network.
Besides containing information about where the enhanced content is located, triggers may also contain a human-readable description of the content. For example, a trigger may contain a description like, "Press Browse for more information about this show...," that can be directly displayed by the receiver, in order to provide information about the nature of the enhancement to the user. Triggers also may contain expiration information to providing the receiver contextual information about how long the enhancement should be offered to the viewer, and a checksum to ensure integrity of the delivered information.
Lastly, triggers may contain JavaScript fragments. These script fragments (oftentimes just single method calls) can trigger execution of JavaScript within the associated HTML page, and can be used for such things as synchronization of the enhanced content with the video signal and and updating of dynamic screen data.
Transports
Besides defining how ATVEF content is displayed and how the receiver is notified of new content, the specification also defines how content is delivered. Because your television or set-top box may or may not have a connection out to the Internet, the ATVEF specification describes two distinct models for delivering content. These two content delivery models are commonly referred to as transports, and the two transports defined by ATVEF are referred to as Transport Type A and Transport Type B.
Transport Type A is defined for ATVEF receivers that maintain a connection (commonly called a back-channel or return path) to the Internet. Generally, this network connection is provided by a dial-up modem, but may be any type of bi-directional access channel. Transport Type A is a method for delivering only triggers without additional content. Because there is no content delivered with Transport Type A, all data must be obtained over the back-channel, using the URLs passed with the triggers as a pointer to the content.
Transport Type B provides for delivery of both ATVEF triggers and its associated content via the broadcast network. In this model, the broadcaster pushes content to a receiver, which will store it in case the user chooses to view it. Transport B uses announcements sent over the network to associate triggers with content streams. An announcement describes a content stream, and may include information regarding bandwidth, storage requirements, and language (enhancements may be delivered in multiple languages).
Since the receiver will, in most cases, need to store any content that will be displayed, it uses announcement information to make content storage decisions. For instance, if a stream requires more storage space than a particular receiver has free, the receiver may elect to discard some older streams, or it may elect not to store the announced stream. A drawback of this model is that if a person chooses to start watching a show near the end, there may not be time for the content to be streamed to the receiver, and the person will not be able to view some or all of the content.
To review, the two types of ATVEF data are triggers and content. If the receiving device has a backchannel to the Internet, Transport Type A will broadcast the trigger (akin to a URL), and content will be pulled over the Internet. If the receiving device does not have an Internet connection, Transport Type B allows both the triggers and content to be delivered over the broadcast medium.
Delivery protocols
As well as defining the transport models for delivering ATVEF data, the specification also defines a reference protocol stack used for content delivery. While all of the high-level protocol layers are well-defined for every ATVEF implementation, the link layer and physical layer protocol layers are dependent on the broadcast network. This is obvious when you consider that it is not possible to transmit analog data over cable the same way you would transmit digital data over satellite. Figure 1 illustrates a standard ATVEF protocol stack for delivery of enhanced content.
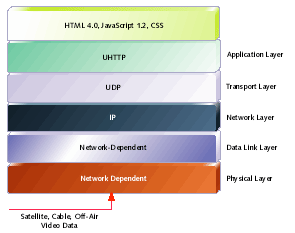
Figure 1. Typical ATVEF protocol stack
For traditional bi-directional Internet communication, the Hypertext Transfer Protocol (HTTP) defines how data is transferred at the application level. But, because one can't have a two-way connection over a broadcast medium, we require a unidirectional application-level protocol for data delivery. ATVEF defines this protocol to be the Unidirectional Hypertext Transfer Protocol (UHTTP). UHTTP is based on UDP, as opposed to TCP. This makes sense, of course, because UDP is a connectionless protocol suitable for a broadcast network.
Like HTTP, UHTTP uses traditional URL naming schemes to reference content. Therefore, content creators can reference enhancement pages using the standard "http:" and "ftp:" naming schemes. To this, ATVEF adds the "lid:," or local identifier URL naming scheme. The "lid:" naming scheme allows content creators to reference content that exists locally (on the receiver's hard drive, for example) as opposed to on the web.
With HTTP, as well as with many other Internet application protocols, the TCP layer provides well-defined error detection and re-transmission facilities. But, for a unidirectional protocol, there is no possibility for retransmission requests. Thus, UHTTP must implement error correction without retransmission, sometimes called Forward Error Correction (FEC). Using sophisticated FEC algorithms, if the data is not too badly corrupted, it can be re-generated with only the received information. With their emphasis on error correction instead of detection, the coding schemes used in unidirectional communications are more similar to the algorithms used in data storage like digital tapes and CD-ROMs, than those used in traditional bi-directional communications.
Bindings
How ATVEF data is delivered over a particular network - from the network layer protocol down to the physical layer - is called the binding. In order for ATVEF to provide interoperability between broadcast networks and receivers, it is important that every network have only one binding. And, it is equally important that each binding provide a fully comprehensive definition of the interface between the broadcast network specification and the ATVEF specification.
At this point, ATVEF has defined bindings for delivering data over IP multicast as well over NTSC. Because the transmission of IP is defined (or can be) for virtually every type of television broadcast network, the binding to IP is considered the reference binding. So, defining an ATVEF binding for a new network could be as easy as describing how to run IP over that network. Figure 1 illustrates the protocol stack for the reference binding.
Below, we include a detailed description of the ATVEF binding to a particular network - NTSC. ATVEF expects other standards bodies to define bindings for other networks.
ATVEF over NTSC
NTSC is the standard for analog television broadcasts in the United States. Unless you have an HDTV set already, the televisions in your home are nothing but NTSC receivers. Part of the NTSC standard defines a frame (image) as consisting of 525 horizontal lines, each line drawn (or scanned) left to right. During a frame scan, only every other line is drawn; therefore, it takes two full screen scans to draw a single frame.
Each time the electron gun in the television's cathode ray tube finishes scanning a half-frame, it must return to the upper left hand corner of the television screen to prepare for the next half-frame. This takes a non-trivial amount of time, so each pass of the electron gun must be synchronized with the incoming signal. This is done by adding a set of unused lines of data to the end of each screen scan, giving the electron gun time to return to its starting position. These 21 extra "lines" make up what is called the Vertical Blanking Interval (VBI). (If you want to see the VBI for yourself, fiddle with the vertical hold knob on your TV and look for a horizontal black stripe across your screen.)
As it turns out, only the first nine lines of the VBI are actually required to reposition the cathode ray. This leaves twelve more lines that can be used to broadcast data. In fact, in the United States, closed captioning data has been broadcast on line 21 for many years. Each line of the VBI has a transmit rate of about 17 kbps. So, in theory, the VBI associated with each NTSC-encoded television channel could carry up to 204 kbps (12 lines at 17 kbps/line) of piggy-back data. However, after taking into account the overhead associated with the various protocol layers and the need to prevent conflicts with closed captioning and other data already broadcast within the VBI space, the maximum achievable rate for ATVEF data transmission is somewhat lower than this-probably around 100 kbps.
Transport Type A
The Type A transport binding for NTSC is very easy to describe: ATVEF triggers are simply broadcast in line 21 of the VBI. For purposes of data integrity, the NTSC binding for Transport Type A requires that each trigger contain a checksum. The binding also recommends that the trigger length not exceed 25% of the total bandwidth of the line, in order to avoid conflicts between triggers, closed captioning data, and data from any future services that might also use line 21.
While ATVEF triggers could have been specified for some other line of the VBI, placing them on line 21 provides advantages for receiver manufactures. For example, most standard NTSC video decoders already have the ability to extract line 21 of the VBI for closed captioning data. So, by placing triggers in the same line, hardware manufactures are not forced to upgrade to more expensive decoders that support data extraction in other lines of the VBI.
Transport Type B
In addition to sending triggers on line 21 of the VBI, the Transport Type B NTSC binding includes a mechanism for delivering IP datagrams over the other VBI lines. IP over VBI (IP/VBI) is an Internet Draft of the Internet Engineering Task Force (IETF). As such, IP/VBI is not yet a standard, just a work in progress. Therefore, some details of some of the encapsulation, compression, and error detection schemes may change, but the architecture is unlikely to change radically. Figure 2 illustrates the protocol stack defined by ATVEF down to the IP layer, and defined by IP/VBI below that.
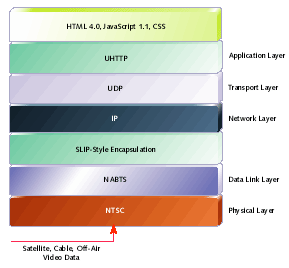
Figure 2. ATVEF over NTSC protocol stack
At the bottom of the stack is the NTSC television standard. At the lowest level, the television signal transports NABTS (North American Basic Teletext Standard) packets. NABTS is a method of modulating data onto the VBI. A typical NABTS packet gets encoded onto a single horizontal scan line (VBI line). NABTS, by way of its own forward error correction, can provide for correction of single bit, double bit, and single byte errors, as well as having the ability to regenerate an entire missing packet. The NABTS packets are removed from the VBI to form a sequential data stream. This data stream - encapsulated in a SLIP-like protocol - is unframed to produce IP packets, which are handled equivalently across all ATVEF network types that implement the IP reference binding.
As you can see, a specific network binding is not complicated, but is detailed enough (the full IP/VBI Draft is obviously much more detailed than what we've presented) that anyone implementing a broadcast network or building an ATVEF receiver has enough information to make their design ATVEF-compliant. And, while we've only presented the NTSC binding for ATVEF here, there is - or soon will be - well-defined ATVEF bindings to every other major video network standard, including PAL and SECAM (the European counterparts to NTSC), ATSC (digital terrestrial broadcast), cable, and satellite.
Design issues
Even for those intimately familiar with the specification, implementing an ATVEF receiver is not a trivial chore. Because the specification is flexible with respect to many of the implementation details, it is up to the embedded software developers -- and in some cases the hardware designers -- to determine exactly how the receiver will be integrated with the television or the rest of the set-top box.
The first major decision when designing an ATVEF receiver is whether to support Transport A or Transport B. Oftentimes, this decision is driven by the type of network the receiver will be utilizing. For a satellite television set-top box that provides no return path to an ISP, the obvious decision is to support Transport B. But, for a cable television set-top box that doubles as a cable modem with dedicated Internet access, it makes sense to support Transport A. Of course, choosing to support a high-bandwidth option like Transport B will also require additional hardware and/or software performance.
As a typical example, let's suppose that we were building a set-top that would serve as an NTSC receiver for ATVEF content. Assuming the standard NTSC binding for Transport B -- NABTS encoding of the data in the VBI -- we must decide how we will decode this data when received. The most obvious choice is to use an NTSC video decoder that will parse all VBI lines in hardware. But, as we mentioned earlier, while some of the higher-end decoders support this functionality, these decoders tend to be a little more expensive; when building millions of set-top boxes, every penny saved can make a big difference in the bottom line.
The other option is to do the NABTS decoding in software. Unfortunately, software decoding is very processor intensive. In fact, some benchmarks have indicated typical VBI decoding requires up to 2% of a Pentium-class 166MHz processor per VBI line. For full decoding of VBI lines 10-20, this would require about 20% of that same processor's time! Of course, these specific issues are only related to NTSC receivers. ATVEF receivers on digital - or non-NTSC analog - networks have a whole set of different issues that must be addressed.
Another major design issue that developers must consider is user interface. By design, the ATVEF specification puts no restriction on how triggers and data are provided to the user. It is up to the implementers to decide how these things are provided to the user. For example, it seems reasonable that the user should be able to decide if he would like to receive indication of incoming enhancements or not. But, there is nothing in the specification that dictates that implementers must allow users to turn off enhancements!
So what?
So, now you're wondering, "What is this enhanced TV stuff going to do for me?" The most obvious answer, unfortunately, is that it is going to try to entice you to spend money. For decades, the television has been used to solicit your hard-earned cash through a seemingly endless stream of commercials. But, despite the annoying jingles that we can't get out of our heads, the slogans that pervade pop-culture, and the famous spokespersons that just won't go away, television advertising has always lacked its creator's most desired ability. It has lacked the ability to "complete the transaction." Never before has television advertising had the means to allow the viewer to make a spontaneous purchase, to buy with the click of a button. It does now.
That doesn't just mean that every commercial will include a "BUY ME NOW" button. It also means that you'll be able to make purchases during your favorite shows. Clicking on Dan Marino's football jersey during Monday Night Football may pop up a description of the collectible garment, with an opportunity to purchase one right away. Or, during that same Monday Night Football game, the network may offer you the option to receive alternate camera footage, live from the home-team's clubhouse or from the camera on the referee's shirt - for a fee, of course.
But let's not just focus on the advertising; enhanced television has the ability to improve your viewing experience as well. Imagine interactive game shows, where the contestants are chosen during the show to participate directly from their living rooms. Or you're watching MTV, and with the click of a button, finally being able to get the lyrics to that ridiculous song you can't stop humming. Imagine choose-your-own-ending television shows where viewers have the option to vote on which of a variety of outcomes will happen.
And not only will television provide enhanced content, it also will have the means to provide personalized content. Take regular NTSC broadcasts, for example. VBI data (and hence ATVEF data) can be added to an NTSC signal at any point, and even more than one point, in the path the signal travels from the broadcaster to the receiver. Therefore, a broadcaster could insert ATVEF content on a national scale, a local cable operator could add ATVEF content relating to local markets, and an automated profiler in your receiver can figure out which specific content would most appeal to you, and display it. National news broadcasters will now have the ability to provide local headlines, or better yet, headlines that appeal specifically to you!
Industry support and competing standards
Enhanced television is not a new idea. For years, companies have built visions of enhanced television and tried to sell their visions to advertisers and consumer electronics manufacturers. However, none of these proprietary systems caught on. Enhanced television has a "chicken and egg problem" - broadcasters are reluctant to invest in an enhanced television content and infrastructure before the consumer electronics companies can provide a reasonable audience size. And the consumer electronics companies find it difficult to sell enhanced TV receivers without the support of the broadcasters, who must provide enhanced content.
Today, there are two main standards competing in the area of enhanced television: ATVEF and Broadcast HTML. Broadcast HTML was created from ATSC-related work to develop the DTV Application Software Environment (DASE). It is a combination of an XML-based subset of HTML 4.0, along with a Java Virtual Machine and Sun's Personal Java API.
Both standards have significant industry support, and neither is likely to disappear soon. That leaves broadcasters-- hoping to avoid a prolonged "VHS vs. Beta" fight--worried. Many are looking to the ATVEF and DASE members to reconcile their differences, or provide a minimum level of interoperability between the standards.
Some companies are not waiting for the standards to settle. CNN, Discovery Channel, and HBO are among a handful of broadcasters already delivering enhanced content on a regular or semi-regular basis. In fact, each week, over 1000 hours of network, syndicated, and cable TV programming include content enhancements. Consumer electronics companies are designing their next-generation set-top boxes to comply with enhanced television specifications. And embedded web browser companies are already providing enhancement television support in their browsers. Regardless of your favorite standard, you can be sure that enhanced television is coming.
Acknowledgments
The authors wish to thank David Mott of Liberate Technologies for reviewing this article for technical accuracy. David has served on the ATVEF Technical Working Group since its inception.
This article was published in the October 1999 issue of Embedded Systems Programming. If you wish to cite the article in your own work, you may find the following MLA-style information helpful:
Steinhorn, Jason and Mark Kohler. "Enhancing TV With ATVEF," Embedded Systems Programming, October 1999, pp. 55-64.