Quite a few embedded programmers are considering adopting the Java programming language. But it's not as easy to run Java programs in an embedded environment as you might think.
In order to execute Java programs in an embedded system, you must integrate a Java runtime environment into your software. Although several commercial runtime environments are now for sale or in beta release, a less expensive and more widely available option is the freeware Kaffe Virtual Machine. In this article, we'll discuss the hardware and operating system requirements of Kaffe and the work involved in porting it to an embedded platform. Along the way, we'll also discuss what to look for in a commercial Java runtime environment, should you decide to go that route instead.
As you probably already know, Java is an easy-to-use, object-oriented programming language designed for platform-independence and protection from common programming mistakes. These and other characteristics help make programming in Java a downright pleasure. But the behind-the-scenes work necessary to support the language at runtime is a lot more than for traditional high-level languages like C, or even C++. For instance, Java is an interpreted language, which means that the equivalent of a runtime compile cycle must be executed on the target processor. Other features that require significant runtime support are garbage collection, dynamic linking, and exception handling.
Java Usage Models
It is currently unrealistic to consider implementing an entire embedded software project in Java. For one thing, Java does not include a mechanism for directly accessing memory or hardware registers. So there will always be a need for device drivers and other pieces of supporting software written in C/C++ or assembly. This other software might either be called from Java—in which case it is said to be a native method—or run as a separate thread of execution, in parallel with the Java runtime environment.
Before preparing your system for Java, it is important to think about how the Java programs you write will fit into your overall architecture. Many Java usage models have been proposed for embedded systems, but it seems that each of them falls into one of four categories: No Java, Embedded Web Server Java, Embedded Applet Java, or Application Java. These four usage models are distinguished by two binary variables: (1) the location of the stored Java bytecodes and (2) the processor on which they are executed. Each of these variables can take one of two values: target (the embedded system) or host (a computer attached to the embedded system). For example, the category No Java includes all scenarios in which the bytecodes are stored on and executed by a host computer; although Java is in use, it is never actually on the embedded system. All four usage models are illustrated in Figure 1.
In the Embedded Web Server usage model the Java bytecodes are stored on the target system (usually in Flash memory or ROM), but executed by the host. This model is useful for networked embedded systems that require a graphical interface. A Java-enabled web browser—running on the host workstation—executes a set of Java bytecodes uploaded from the embedded system. In addition to the Java bytecodes, the embedded system in this scenario must store at least one HTML file and execute a piece of software called an embedded web server. However, since Java is not actually executed on the embedded system, a Java runtime environment is not required there.
The third and fourth usage models are the most interesting from the viewpoint of this article. These are the ones in which Java bytecodes are actually executed on the target processor and for which an embedded Java runtime environment is therefore required. In the Embedded Applet scenario, the Java bytecodes are stored on the host workstation and sent to the embedded system over a network. The embedded system executes the bytecodes and sends the results back to the host. Embedded applets could be used to implement network management functionality (as a replacement for SNMP, for example) or to off-load computations from one processor to another.
In the Application model, Java comprises some or all of the actual embedded software. The Java bytecodes are stored in a nonvolatile memory device and executed by the Java runtime environment in much the same way that native machine code is fetched and executed by the processor itself. This use of Java is most similar to the way C and C++ are used in embedded systems today—to implement large pieces of the overall software. However, because Java lacks the ability to directly access hardware, it may still be necessary to rely on native methods written in C or C++. This is not unlike the way C programmers use assembly-language to perform processor-specific tasks.

Figure 1. Four Java usage models for embedded systems
Java Runtime Environments
A typical Java runtime environment for embedded systems contains the following components:
- A Java Virtual Machine to translate Java’s platform-independent bytecodes into the native machine code of the target processor and to perform dynamic class loading. This can take the form of either an interpreter or a just-in-time compiler (JIT). The only real difference between the two is the speed with which the bytecodes are executed; a JIT is faster because it avoids reinterpreting previously executed sections of the program.
- A standard set of Java class libraries, in bytecode form. If your application doesn’t reference any of these classes, then they are not strictly required. However, most Java runtime environments are designed to conform to one of Sun’s standard API’s, such as PersonalJava or EmbeddedJava.
- Any native methods required by the class libraries or virtual machine. These are functions that are written in some other language, precompiled, and linked with the Java virtual machine. They are primarily required to perform functions that are either processor-specific or unable to be implemented directly in Java.
- A multitasking operating system to provide the underlying implementation of Java’s threading and thread synchronization mechanisms.
- A garbage collection thread. The garbage collector runs periodically—or whenever the pool of dynamic memory is unable to satisfy an allocation request—to reclaim memory that has been allocated but is no longer being used by the application.
The relationship of these components to the other software and hardware in a typical embedded system is illustrated in Figure 2. A dotted line surrounds the Java runtime environment.
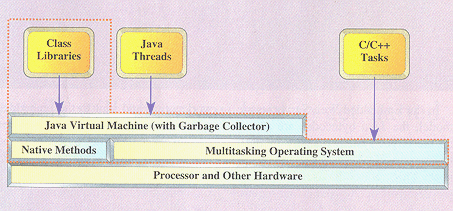
Figure 2. Components of a typical Java runtime environment
Kaffe
Kaffe is a freeware Java runtime environment that can be downloaded from http://www.kaffe.org. The virtual machine (source code for both an interpreter and a JIT are included), garbage collector, and native methods that comprise Kaffe are themselves written in C and assembly. So, although Kaffe was not written with embedded systems in mind, it should be possible to port it to any platform for which there exists an ANSI C compiler.
Kaffe’s list of currently supported processors reads like a who’s who of the 32-bit world: 386/486/Pentium, SPARC, Alpha, PowerPC, 68k, and MIPS. These are the same processor families supported by the GNU C Compiler (though GCC supports several others, as well). If your embedded processor is from one of these families, your Kaffe port should be pretty simple. Otherwise, a bit more effort will be required to get Kaffe up and running.
As for memory, a typical combination of the interpreter, garbage collector, and native methods requires less than 100-kbytes of code space. Add to that the size of your application and any class libraries it requires (both stored in Java bytecodes) to calculate the overall ROM requirements for your Java program. You’ll also need a large heap for dynamic memory allocation. The precise amount of heap space you’ll need is dependent upon your application. A good rule of thumb is that you shouldn’t try to use Java in a system with less than 1-Mbyte of RAM.
Kaffe can be used with or without an operating system, a feature that is somewhat unique among Java virtual machines. This is only possible because Kaffe contains its own internal threads implementation that requires very little support from the underlying software environment. By default, it uses this package to create and multitask Java threads.
Real-time JavaAs you may know, Java is not ideally suited for use in real-time systems. Functions written in Java execute more slowly and less deterministically than similar functions written in C or C++. However, that does not mean you should avoid Java altogether in such systems. When writing Java programs, it is common practice to partition one’s software into multiple threads of execution. These threads are analogous to the tasks provided by a real-time operating system. And, in fact, many Java virtual machines rely on the underlying operating system to make scheduling decisions and perform context switching. So, it is not unreasonable to consider partitioning an embedded application into a set of Java threads and a set of real-time tasks written in C/C++ or assembly. By allocating task priorities such that all of the Java threads (including the garbage collector) have a lower priority than the least-important real-time task, it is possible to benefit from Java without paying a performance penalty. Because Java is such a nice programming language to use, a lot of work is being done to make it more suitable for real-time software development. This includes more deterministic garbage collection algorithms and language extensions to allow direct implementation of hard real-time tasks. One such effort is being headed by Dr. Kelvin Nilsen of NewMonics, Inc. |
Kaffe Porting Process
It would be impossible to give detailed, step-by-step instructions for porting Kaffe to any and every embedded system imaginable. So we will attempt only to provide an overview of this process, the details of which are taken from the latest release of Kaffe, version 0.9.2. By following these directions, it should be possible for an embedded software engineer to complete a Kaffe port within a few weeks—longer if the JIT needs to be ported and/or a native threads implementation is desired.
After downloading Kaffe and unarchiving the tar’ed and gzip’ed file, you will see that the source code is organized into the following subdirectories:
- kaffe - platform-independent parts of the interpreter and JIT and source code for the garbage collector, dynamic class loader and other pieces of the Java runtime environment.
- config - platform-dependent parts of the interpreter and JIT. This is organized into a set of subdirectories for supported processors, with operating system-specific directories below those.
- packages - the Java class libraries and any native methods they depend on. Only the native methods are provided in the standard Kaffe distribution. For various legal reasons, the actual class libraries must be obtained from Sun Microsystems or another vendor.
- include - interface definitions for the native methods provided in the above directory. Some of this information is required by the platform-independent files.
The partitioning of the Kaffe source code into platform-independent and platform-dependent subdirectories is intended to simplify the process of porting it to new platforms. In most cases, only files in the config directory require modification. However, embedded systems differ significantly from other computers in that they rarely have filesystems or UNIX-like operating systems. So we will see that there may be some good reasons to modify the "platform-independent" code as well.
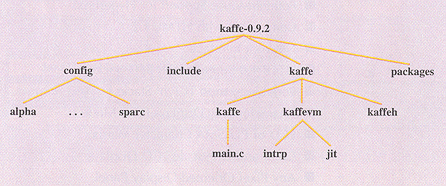
Figure 3. Organization of the Kaffe source code
Step 1: Bytecode interpreter
Kaffe’s bytecode interpreter is an incredible piece of software. Rather than mapping Java bytecodes to blocks of processor-dependent assembly code, the authors of Kaffe have cleverly implemented each bytecode in C. As a result, not a single line of the interpreter source code is processor-specific. This makes porting the basic (non-JIT) virtual machine simple: just use your cross compiler to build the files in the directory kaffe/kaffevm.
When you compile the files in this directory, you will also be building the garbage collector, dynamic class loader, and other parts of the Java runtime environment that are either independent of the processor or rely on the functions in the processor-dependent parts of the Kaffe source code. At this point, be sure to compile the contents of the kaffevm/intrp directory and avoid building the files in kaffevm/jit.
Step 2: Internal threads
As we stated earlier, Kaffe has its own internal threads package. In other words, it maintains its own thread data structures and performs scheduling and context switching at the appropriate times. This functionality is separate from and invisible to the underlying operating system. But as in an operating system, the code that performs these functions is largely processor-dependent. So, to get the internal threading package up and running on an unsupported processor, some assembly may be required.
All of the required changes will take place in the config directory. First, create a subdirectory with the name of your processor. Then, in that subdirectory, create a file called threads.h that defines the two constants and four macros described below. These constants and macros are used by the processor-independent portion of the threads package and may be written in C or assembly, or some combination thereof.
- USE_INTERNAL_THREADS should be defined to enable the internal threads package.
- THREADSTACKSIZE is a constant that defines the size of each thread’s stack, in bytes.
- THREADINIT(ctx * pContext, void (*func)()) performs context initialization for a new thread. The entry point of the thread is provided by the function pointer.
- THREADSWITCH(ctx * pNewContext, ctx * pOldContext) performs an actual context switch.
- THREADINFO(ctx * pContext) resets the entire task control block during Kaffe initialization.
- THREADFRAMES(thread * taskId, int count) returns the number of active stackframes in count.
Examples of various ports of Kaffe’s threading package can be found in the config directory. These code examples provide an excellent starting point for ports to new processors. The i386 subdirectory is a particularly good place to start, since it contains a setjmp style implementation with very little assembly code.
Step 3: Supporting software
Like most other software written in C, Kaffe depends on routines in the standard C library. The majority of these dependencies are benign—in other words, they are compatible with embedded systems. These are the functions like strcmp(), atoi(), sin(), etc. that you probably use everyday. However, some of the library routines on which Kaffe depends may not be supported by all C compilers or may not work in an embedded environment. Here is a list of the supporting software that you may need to provide:
- Dynamic memory allocation. Although Java programmers do not directly call malloc(), the Kaffe virtual machine does require a memory allocation routine to request large pools of memory from the underlying software.
- Signals. Kaffe relies on a POSIX-compliant signals implementation to perform the equivalent of software interrupts. These are used to awake sleeping threads and handle exceptions.
- A non-blocking I/O interface, similar to select().
If you are running Kaffe over an embedded operating system, the necessary functionality may already be available. If not, you will need to either provide it yourself or modify the appropriate Kaffe source code.
Step 4: Dynamic class loader
One part of the "platform-independent" source code that must be modified for use in any embedded system is the dynamic class loader. This is a part of the Java runtime environment that is responsible for loading methods as they are called. In a desktop environment, the bytecodes associated with each method is stored in a class file. The dynamic class loader searches the directories and files in the class path for a method by the given name. But there are very few embedded systems with filesystems, so the class loader must be modified to search for class files in memory (either RAM or ROM).
You have two options at this point. One is to create a filesystem in memory and keep the dynamic class loader largely unchanged. The other is to rewrite the dynamic class loader completely, perhaps replacing it with a lookup table that maps class or method names to their starting addresses in memory. Either way, most of the functions that require changes reside in the two files classMethod.c and lookup.c in the kaffe/kaffevm directory.
Step 5: Just-in-time compiler (optional)
If Kaffe’s JIT already supports your processor, you might want to consider using it at this time. To do so, rebuild the contents of kaffe/kaffevm, this time using the files in kaffevm/jit rather than kaffevm/intrp. Note that these files depend on those in the config/<processor> directory, which should be compiled first.
If your processor is not currently supported by Kaffe’s JIT, we’d recommend that you use the interpreter instead. A port of Kaffe’s JIT could take a significant effort on your part and is probably better left in the hands of an experienced compiler writer—particularly if you are concerned about performance. If you opt to attempt a JIT port, take a look at the files in the processor-specific directories under config. The implementation for SPARC processors is particularly well documented.
Step 6: Native threads (optional)
By default, Kaffe relies on its own internal threading mechanisms to initialize, track, and schedule each of the threads within a Java application. Kaffe accomplishes this by creating thread data structures that are separate from and invisible to the underlying multitasking operating system (if one exists at all). In other words, the Kaffe virtual machine is itself a task that subdivides its execution time and gives each slice to one of the Java threads. Figure 4 illustrates the relationship of Kaffe’s threads to the tasks of an underlying operating system.
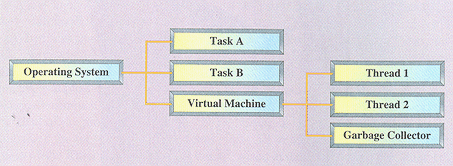
Figure 4. Relationship of Kaffe’s threads to the tasks of the underlying operating system
Some other Java runtime environments allow the underlying operating system to create and control their threads. This type of an implementation is said to use native threads, because the Java threads are native to the underlying operating system. In this case, the Java runtime environment is itself broken up into several tasks: one for the garbage collector, one for the virtual machine (interpreter or JIT) and one for each application thread. This allows Java threads to better compete for use of the embedded processor.
The current release of Kaffe does not include a native threads interface that can be easily ported (although the next release is expected to include one). So if you want to use native threads with Kaffe right now, you’ll actually have to rewrite some parts of the virtual machine. If you have a thorough understanding of your operating system’s threading API, it is possible to have Kaffe use native threads instead. In fact, at least one embedded operating system vendor—Lynx Real-Time Systems—is working on a port of Kaffe to its proprietary threads interface.
Step 7: Virtual machine startup
As distributed, Kaffe expects to be compiled for a DOS or UNIX-like operating system and invoked from the command line, usually with a parameter telling it which Java class to execute first. But we want to use Kaffe in an embedded system, so we’ll need a less dynamic way to start the virtual machine and a mechanism to pass the startup class name to it. The initialization can be accomplished with a call to the routine initializeKaffe(). This will start the dynamic class loader, virtual machine, and garbage collector and would typically be done from within main().
Once the Kaffe runtime environment has been initialized, it is ready to execute Java bytecodes. However, it will not yet know what bytecodes to execute. You must provide that information, by calling the routine do_execute_java_class_method(). This routine calls the dynamic class loader, which will locate the actual bytecodes. In addition, a new thread is created for their execution. This call could be made from main() or at a later time, possibly in response to a network request to execute an embedded applet.
Commercial Alternatives
If you want to integrate Java into your embedded environment, Kaffe is not your only option. A number of real-time operating system vendors are now offering complete Java runtime environments based on their own proprietary kernels. These packages have already been ported and are more or less turn-key solutions. Some of the most prominent such vendors are Wind River Systems, Accelerated Technology, and Microware.
When deciding if a commercial package is the right solution for you, consider the following advantages and disadvantages compared with Kaffe. The first advantage is that of shorter time-to-market; a prepackaged Java runtime environment will likely reduce your development effort by several weeks to a month. In addition, if you run into any problems or bugs, technical support is just a phone call away. Another advantage is that most third-party Java runtime environments use the native threads of the underlying RTOS; this is a more robust implementation than the internal threads package included with Kaffe.
There are also several reasons why a third-party solution may not be right for you. The most prominent disadvantage is cost. Not only are most commercial Java runtime environments expensive to license, but you may be required to pay additional royalties (to Sun Microsystems) based on the number of units you ship. Also, third-party vendors often do not (or cannot) provide the source code for their virtual machines. So, you won’t be able to muck around with the internals to enhance the performance of your application. The third issue—and it’s not clear if this is a disadvantage or merely an aside—is compatibility. If you’re currently using a home-grown operating system, or one for which commercial Java support is not currently available, you may have no choice but to use Kaffe.
If you do decide to purchase a commercial Java runtime environment, here are some of the things you should look for:
- Support for native threads and the operating system of your choice.
- Compatibility with the latest release of Sun’s Java Development Kit (JDK).
- Ability to load class files directly from ROM. Beware of implementations that require an external filesystem, as these may not be compatible with your system.
- JIT support for your processor. Unfortunately, we don’t know of any commercial vendor that has a JIT for embedded systems. Hopefully this will change in the near future.
- A modular design that can be scaled to balance the needs of your application and the constraints of your hardware.
Java Class Libraries
As we said earlier, a Java runtime environment includes a set of standard class libraries. But these Java classes are not strictly required unless your application actually uses them. In that sense, they are very similar to the standard C and C++ libraries. For example, if you’ve ever used strcmp() or strlen() in an embedded program, you were relying on the standard C library to be linked with your application. Similarly, if you want to manipulate strings in Java, you will need a class library called java.lang in your runtime environment.
In order to promote and encourage the "Write Once, Run Anywhere" nature of Java, Sun has defined several standard groups of class libraries. Sun refers to these standard API’s as Java Application Environments. So far, four such standards have been announced:
- Standard Java - the full set of class libraries included in Sun’s most recent release of the JDK. These classes are appropriate for desktop workstations and servers and may require significant hardware and operating system resources.
- PersonalJava - a (not-quite proper) subset of the Standard Java API that is appropriate for set-top boxes, PDAs, network computers, and other networked embedded systems with significant processing power and memory.
- EmbeddedJava - a subset of the PersonalJava API that is better suited to the resource-constrained environments typically found in non-networked and relatively inexpensive embedded devices. Although the details of this API have not yet been released, the most likely changes are the elimination of java.awt (a windowing package) and the reclassification of java.net as optional.
- Java Card - a specification for the use of Java in smart cards and other systems with very small amounts of memory. Sun claims that a Java Card-compliant runtime environment can be created in systems with as little as 16-kbytes of ROM, 8-kbytes of EEPROM, and 256 bytes of RAM!
The intention of these standard API’s is to allow application developers to easily specify the type of platform on which their Java program will run. For example, a program written for use in a PersonalJava-compatible set-top box could also be run on a network computer or PDA.
Ready, Set, Go
In an earlier article on embedded Java, Michael concluded by saying that "embedded developers should probably adopt a wait-and-see attitude toward Java." But a lot has changed, and it now seems reasonable to stop waiting and start trying it out. If you have some time available, we highly recommend that you get a copy of the Kaffe source code and Sun’s JDK and start playing with them—even if you don’t actually port Kaffe to your embedded platform. There can be no substitute for first-hand experience, and the things you learn will no doubt help you make more informed decisions regarding your use of Java in future projects.
That said, we’d like to reiterate that the minimum system requirements for accomplishing something useful with Java are currently a 32-bit processor, 1-Mbyte of RAM, and a similar amount of ROM. While it may be possible to port Kaffe to a 16-bit processor and/or a system with less memory, we don’t know of anyone who has yet done that successfully. But perhaps if you wait another nine months this too will seem like old news.
Further Reading
There is an incredible wealth of information about Java available both on the Internet and on paper. To help you explore the subjects introduced here a bit further, we provide the following list of resources we found helpful while preparing this article.
- Arnold, Ken and James Gosling. The Java Programming Language< Reading, MA: Addison-Wesley, 1996.
- Barr, Michael and Brian Frank, "Java: Too Much for Your System?" Embedded Systems Programming, May 1997, p. 24.
- Bunnell, Mitchell, "Mixing Java and C in Embedded Systems," Proceedings of the Embedded Systems Conference, San Jose, September-October 1997, p. 901.
- Dibble, Peter C, "Java in Embedded Systems," Proceedings of the Embedded Systems Conference, San Jose, September-October 1997, p. 55.
- Howard, David M, "Multithreading in the Java Language," Embedded Systems Programming, October 1997, p. 82.
- Lindholm, Tim and Frank Yellin. The Java Virtual Machine Specification. Reading, MA: Addison-Wesley, 1997.
- Meyer, Jon and Troy Downing. Java Virtual Machine. Sebastopol, CA: O’Reilly & Associates, 1997.
- Oaks, Scott and Henry Wong. Java Threads. Sebastopol, CA: O’Reilly & Associates, 1997.
- Quinnell, Richard A., "Java Perks Up Embedded Systems," EDN, August 1, 1997, p. 38.
- kaffe.org - the main starting point for Kaffe source code, related news, and mailing list info.
- Newmonics - one of the companies that is researching real-time Java. Unlike most of the others, this one actually has products for sale now and others on the way.
Acknowledgments
The authors wish to thank Tim Wilkinson for reviewing a draft of this article and providing information about future releases of Kaffe. Tim is the primary author and maintainer of the Kaffe source code and a founder of Transvirtual Technologies, Inc., a company that develops commercial Java runtime environments based on this software.
This article was published in the February 1998 issue of Embedded Systems Programming. If you wish to cite the article in your own work, you may find the following MLA-style information helpful:
Barr, Michael and Jason Steinhorn. "Kaffe, Anyone? Implementing a Java Virtual Machine," Embedded Systems Programming, February 1998, pp. 34-46.