Finding and killing latent bugs in embedded software is a difficult business. Heroic efforts and expensive tools are often required to trace backward from an observed crash, hang, or other unplanned run-time behavior to the root cause. In the worst case scenario, the root cause damages the code or data in such a subtle way that the system still appears to work fine or mostly fine-for some time before the malfunction.
Too often engineers give up trying to discover the cause of infrequent anomalies--because they can't be easily reproduced in the lab--dismissing them as "user errors" or "glitches." Yet these ghosts in the machine live on.
So here's a guide to the most frequent root causes of difficult-to-reproduce firmware bugs.
#10: Jitter
Some real-time systems demand not only that a set of deadlines be always met but also that additional timing constraints be observed in the process. Such as managing jitter.
An example of jitter is shown in Figure 1. Here a variable amount of work (blue boxes) must be completed before every 10 ms deadline. As illustrated in the figure, the deadlines are all met. However, there is considerable timing variation from one run of this job to the next. This jitter is unacceptable in some systems, which should either start or end their 10 ms runs more precisely.
 |
Figure 1. An example of jitter in the timing of a 10ms task
If the work to be performed involves sampling a physical input signal, such as reading an analog-to-digital converter, it will often be the case that a precise sampling period will lead to higher accuracy in derived values. For example, variations in the inter-sample time of an optical encoder’s pulse count will lower the precision of the velocity of an attached rotation shaft.
Best Practice: The most important single factor in the amount of jitter is the relative priority of the task or ISR that implements the recurrent behavior. The higher the priority the lower the jitter. The periodic reads of those encoder pulse counts should thus typically be in a timer tick ISR rather than in an RTOS task.
Figure 2 shows how the interval of three different 10 ms recurring samples might be impacted by their relative priorities. At the highest priority is a timer tick ISR, which executes precisely on the 10 ms interval. (Unless there are higher priority interrupts, of course.) Below that is a high-priority task (TH), which may still be able to meet a recurring 10-ms start time precisely. At the bottom, though, is a low priority task (TL) that has its timing greatly affected by what goes on at higher priority levels. As shown, the interval for the low priority task is 10 ms +/- approximately 5 ms.
Figure 2. The effect of priority on jitter
#9: Incorrect Priority Assignment
Get your priorities straight! Or suffer the consequence of missed deadlines. Of course, I’m talking here about the relative priorities of your real-time tasks and interrupt service routines. In my travels around the embedded design community, I’ve learned that most real-time systems are designed with ad hoc priorities.
Unfortunately, mis-prioritized systems often “appear” to work fine without discernibly missing critical deadlines in testing. The worst-case workload may have never yet happened in the field or there is sufficient CPU to accidentally succeed despite the lack of proper planning. This has lead to a generation of embedded software developers being unaware of the proper technique. There is simply too little feedback from non-reproducible deadline misses in the field to the original design team—unless a death and a lawsuit forces an investigation.
Best Practice: There is a science to the process of assigning relative priorities. That science is associated with the “rate monotonic algorithm,” which provides a formulaic way to assign task priorities based on facts. It is also associated with the “rate monotonic analysis,” which helps you prove that your correctly-prioritized tasks and ISRs will find sufficient available CPU bandwidth between them during extreme busy workloads called “transient overload.” It’s too bad most engineers don’t know how to use these tools.
There’s insufficient space in this column for me to explain why and how RMA works. But I’ve written on these topics before and recommend you start with Introduction to Rate-Monotonic Scheduling and then read 3 Things Every Programmer Should Know About RMA.
Please know that if you don’t use RMA to prioritize your tasks and ISRs (as a set), there’s only one entity with any guarantees: the one highest-priority task or ISR can take the CPU for itself at any busy time—barring priority inversions!—and thus has up to 100% of the CPU bandwidth available to it. Also note that there is no rule of thumb about what percentage of the CPU bandwidth you may safely use between a set of two or more runnables unless you do follow the RMA scheme.
#8: Priority Inversion
A wide range of nasty things can go wrong when two or more tasks coordinate their work through, or otherwise share, a singleton resource such as a global data area, heap object, or peripheral’s register set. In the first part of this column, I described two of the most common problems in task-sharing scenarios: race conditions and non-reentrant functions. But resource sharing combined with the priority-based preemption found in commercial real-time operating systems can also cause priority inversion, which is equally difficult to reproduce and debug.
The problem of priority inversion stems from the use of an operating system with fixed relative task priorities. In such a system, the programmer must assign each task it’s priority. The scheduler inside the RTOS provides a guarantee that the highest-priority task that’s ready to run gets the CPU—at all times. To meet this goal, the scheduler may preempt a lower-priority task in mid-execution. But when tasks share resources, events outside the scheduler’s control can sometimes prevent the highest-priority ready task from running when it should. When this happens, a critical deadline could be missed, causing the system to fail.
At least three tasks are required for a priority inversion to actually occur: the pair of highest and lowest relative priority must share a resource, say by a mutex, and the third must have a priority between the other two. The scenario is always as shown in the figure below. First, the low-priority task acquires the shared resource (time t1). After the high priority task preempts low, it next tries but fails to acquire their shared resource (time t2); control of the CPU returns back to low as high blocks. Finally, the medium priority task—which has no interest at all in the resource shared by low and high—preempts low (time t3). At this point the priorities are inverted: medium is allowed to use the CPU for as long as it wants, while high waits for low. There could even be multiple medium priority tasks.
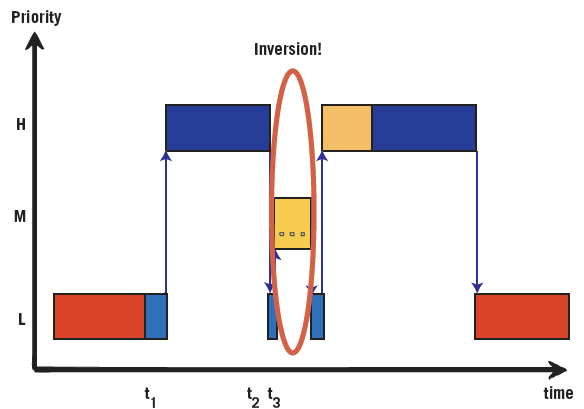 |
Figure 3. An example of priority inversion
The risk with priority inversion is that it can prevent the high-priority task in the set from meeting a real-time deadline. The need to meet deadlines often goes hand-in-hand with the choice of a preemptive RTOS. Depending on the end product, this missed deadline outcome might even be deadly for its user!
One of the major challenges with priority inversion is that it’s generally not a reproducible problem. First, the three steps need to happen—and in that order. And then the high priority task needs to actually miss a deadline. One or both of these may be rare or hard to reproduce events. Unfortunately, no amount of testing can assure they won’t ever happen in the field.
Best Practice: The good news is that an easy three-step fix will eliminate all priority inversions from your system. Choose an RTOS that includes a priority-inversion work-around in its mutex API. These work-arounds come by various names, such as priority inheritance protocol and priority ceiling emulation. Ask your sales rep for details.
Only use the mutex API (never the semaphore API, which lacks this work-around) to protect shared resources within real-time software.
Take the additional execution time cost of the work-around into account when performing the analysis to prove that all deadlines will always be met. The method for doing this varies by the specific work-around.
Note that it’s safe to ignore the possibility of priority inversions if you don’t have any tasks with consequences for missing deadlines.
#7: Deadlock
A deadlock is a circular dependency between two or more tasks. For example, if Task 1 has already acquired A and is blocked waiting for B while Task 2 has previously acquired B and is blocked waiting for A, neither task will awake. Circular dependencies can occur at several levels in the architecture of a multithreaded system (for example, each task is waiting for an event only the other will send) but here I am concerned with the common problem of resource deadlocks involving mutexes.
Best Practice: Two simple programming practices are each able to entirely prevent resource deadlocks in embedded systems. The first technique, which I recommend over the other, is to never attempt or require the simultaneous acquisition of two or more mutexes. Holding one mutex while blocking for another mutex turns out to be a necessary condition for deadlock. Holding one mutex is not, by itself, a cause of deadlock. (In theory, a task that wants one mutex could starve while a series of higher priority tasks take turns with that mutex. However, the method of rate monotonic analysis described above takes this possibility into account and ensures this starvation doesn’t happen to tasks with deadlines that must be met.)
In my view, the practice of acquiring only one mutex at a time is also consistent with an excellent architectural practice of always pushing the acquisition and release of mutexes into the leaf nodes of your code. The leaf nodes are the device drivers and reentrant libraries. This keeps the mutex acquisition and release code out of the task-level algorithmics and helps to minimize the amount of code inside critical sections. An additional benefit of this architectural pattern is that it reduces the number of programmers on the team who must remember to use and correctly use each mutex. Other benefits are that each mutex handle can be hidden inside the leaf node that uses it and that doing this allows for easier switches between interrupt disables and mutex acquisition as appropriate to balance performance and task prioritization. One of the most famous priority inversions happened on Mars in 1997. Glitches were observed in Earth-based testing that could not be reproduced and were not attributed to priority inversion until after the problems on Mars forced investigation. For more details, read Glenn Reave’s “What really happened on Mars?” account.
The second technique is to assign an ordering to all of the mutexes in the system (for example, alphabetical order by mutex handle variable name) and to always acquire multiple mutexes in that same order. This technique will definitely remove all resource deadlocks but comes with an execution-time price. I recommend removing deadlocks this way only when you’re dealing with large bodies of legacy code that can’t be easily refactored to eliminate the multiple-mutex dependency.
#6: Memory Leak
Eventually, systems that leak even small amounts of memory will run out of free space and subsequently fail in nasty ways. Often legitimate memory areas get overwritten and the failure isn’t registered until much later. This happens when, for example, a NULL pointer is returned by a failed call to malloc() and the caller blindly proceeds to overwrite the interrupt vector table or some other valuable code or data starting from physical address 0x00000000.
Memory leaks are mostly a problem in systems that use dynamic memory allocation. (Note that unlike the fragmentation described next, memory leaks can happen even with fixed-size allocators.) And memory leaks are memory leaks whether we’re talking about an embedded system or a PC program. However, the long-running nature of embedded systems combined with the deadly or spectacular failures that some safety-critical systems may have make this one bug you definitely don’t want in your firmware.
Memory leaks are a problem of ownership management. Objects allocated from the heap always have a creator, such as a task that calls malloc() and passes the resulting pointer on to another task via message queue or inserts the new buffer into a meta heap object such as a linked list. But does each allocated object have a designated destroyer? Which other task is responsible and how does it know that every other task is finished with the buffer?
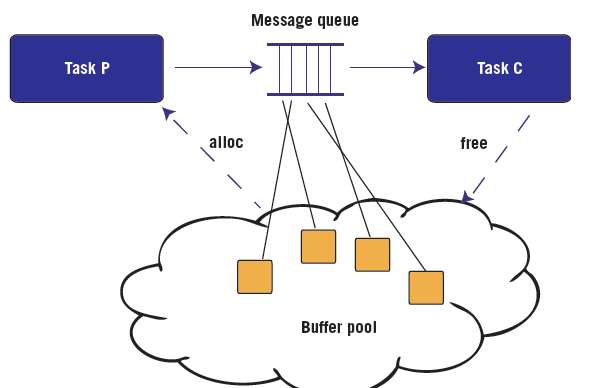 |
Figure 4. A simple design pattern with clear memory buffer ownership
Best Practice: There is a simple way to avoid memory leaks and that is to clearly define the ownership pattern or lifetime of each type of heap-allocated object. The figure above shows one common ownership pattern involving buffers that are allocated by a producer task (P), sent through a message queue, and later destroyed by a consumer task (C). To the maximum extent possible this and other safe design patterns should be followed in real-time systems that use the heap.
In addition to avoiding memory leaks, the design pattern shown in Figure 4 can be used to ensure against “out-of-memory” errors, in which there are no buffers available in the buffer pool when the producer task attempts an allocation. The technique is to (1) create a dedicated buffer pool for that type of allocation, say a buffer pool of 17-byte buffers; (2) use queuing theory to appropriately size the message queue, which ensures against a full queue; and (3) size the buffer pool so there is initially one free buffer for each consumer, each producer, plus each slot in the message queue.
Read on to learn about the Top 5 Causes of Nasty Embedded Software Bugs...
Barr Group's engineers bring this same firmware rigor to the courtroom. See how a firmware defect was proven in the Toyota unintended acceleration case.