Unexpected power loss and software bugs can undermine the reliability of non-volatile data. Fortunately, there are various ways to make non-volatile data resilient to such corruption.
Many devices forget their settings when they power off. Ironically, my washing machine, which uses a mechanical timer, will restart after an accidental loss of power exactly where it left off. My much more sophisticated microwave will completely forget where it was, since it is controlled by software and has no persistent storage. Other examples, such as a VCR that forgets the time at which to record a favorite show, can be slightly more irritating.
On consumer devices, the lack of some form of persistent memory is annoying, and the companies that really care about usability go to the trouble of adding one extra chip to save their customers hours of frustration. For equipment with more serious responsibilities, losing calibration data may mean sending it back to the factory. When we do add a chip to record information, we have to consider how we can be sure that the data on that chip is reliable, and whether the system has been power-cycled or reset for some other reason.
Several articles in Embedded Systems Design magazine have covered the hardware required to record data persistently. 1, 2 However, most discussions explore the hardware design options, without giving much consideration to the software concerns. A number of hardware technologies, such as EEPROM or NVRAM, can guarantee that bits are preserved through a power cycle, but that is no guarantee that the data is valid and useful.
For example, say I'm halfway through updating a 4-byte integer when the software halts. After reset, the value present is two bytes from the new value and two bytes from the old. Similarly, a large data structure may have to be internally consistent. If I am updating the speed of a motor and its direction, I better update both fields or neither. In short, these are the same data consistency problems most embedded engineers have encountered when using interrupts or multitasking.
This article will discuss various failure modes, and methods to detect whether data has become invalid. We will then examine the options of using default values if data is lost, and we will examine the use of double buffering to minimize the chance of losing the data.
Power-fail interrupt
One approach to this issue is to tie an interrupt to a circuit that detects when the supply voltage is dropping, giving the processor a few milliseconds to store the non-volatile data. This route is fraught with dangers. You have to be sure that you always have enough time to store all of the data. If you are dependent on a capacitor to supply power for those few milliseconds, then you need to measure how long the capacitor can supply power under all possible loading conditions, and allow for tolerances and aging of the capacitor. If the data is stored in a serial EEPROM device it may take a considerable length of time to complete the write. If the software is changed later to store more data on the EEPROM, the time lapse between the warning interrupt and the loss of power may have to be reexamined.
The worst property of using an interrupt in this way is that you need to disable the interrupt while the data is being manipulated, otherwise the copy of data in RAM may be inconsistent when the interrupt routine decides to store it. Of course, disabling the interrupt for t microseconds means that we might not get to run the interrupt routine until t microseconds after the power-down event was detected by the circuit. This is t microseconds that need to be added to the minimum amount of warning that the power-loss detection circuit has to give us. As you can see, the potential for race conditions is getting worse.
I once worked on a system that used a backup battery. When the interrupt arrives, telling software that someone has turned off the power switch, the software does its tidy up and then, via an I/O line, instructs the battery circuit to turn off. This means that software is saying "turn off now," rather than allowing itself to be a victim of the timing of an external circuit. This is a nice trick, and resolves some power-down issues, but it does not give any guarantee that persistent data will be valid after the next power-on. Nor does it address the other reasons for resetting software, such as assertion failures, watchdog timeouts, and addressing exceptions due to bad pointers. These resets are due to bugs, and in many large projects it's impossible to guarantee that no bugs are lurking in the system.
In summary, using a power-down interrupt is an acceptable solution if we assume that our software has no bugs. It is reasonable to make this assumption if the software is very simple and the cost of losing the data in EEPROM is small. For many products, neither factor applies.
Checksums
Once we have established that not all resets will be graceful, we need to checksum the data in some way. A cyclic redundancy check (CRC) will provide better error detection properties than an addition-based checksum such as the internet checksum. A full discussion of possible algorithms can be found in Ross Williams's "A Painless Guide to CRC Error Detection Algorithms," as well as several articles by Michael Barr. 3, 4, 5, 6
Non-volatile data storage policy
It is not sufficient to store the data following a power-fail interrupt, so we need to decide when we should store the data. One option is to write the data every time it changes. Another is to write the data on a regular basis, say once per minute. Your policy will depend on three factors.
The first factor is whether you have a complete copy of the data in ordinary RAM. This in turn depends on the speed of reading the device and how often it is read. The second factor is the ratio of reads to writes on that data. If the ordinary RAM copy changes rarely, writing it to persistent storage once per minute may be a waste of cycles and could actually increase the chances that it will become corrupt. The third factor will be the size of the block of data that you must write. This size will dictate the amount of time spent writing to persistent storage, and hence how vulnerable you are to a reset that would leave that data corrupted.
The size of this block is closely related to your checksum method. Let's say you have a 4KB block of persistent storage and you use the last two bytes of the 4KB block as a checksum. Now you want to change 10 bytes. After the change, you will need to iterate through the entire block if you want to generate a new checksum. If reading the persistent storage is slow (say a serial EEPROM), this operation is costly. If we assume that we keep a copy of the 4KB in RAM, calculating the checksum will be quicker. But you still have to be careful when multitasking, since no other task can manipulate the data while the checksum is being calculated.
This scenario gives us reason to break up the 4KB block into a number of smaller blocks, each of which have their own checksum. If each block is a related group with similar read/write ratio, then each of these smaller blocks can have their own policy. The calibration data might get stored each time it changes, but the user settings might get stored once per minute.
Non-volatile data recovery policy
Assume we have just reset and, reading the non-volatile memory, we find that the checksum is not valid. We need some policy to decide what values to apply. We could apply default settings. If the user can easily change the settings, then this may be quite acceptable. If the television occasionally forgets what volume it was set to before the power-cut, the user will not be too bothered. Other scenarios are more serious.
I read one report of an airbag being deployed in a car accident and fatally injuring a child in the front seat. The owners had requested that the passenger side airbag be disabled, and this was performed by the mechanic. The airbag was disabled by setting a flag in EEPROM. The electrically noisy automotive environment led to the EEPROM data being corrupted and the values were reset to defaults. In its default state, the airbag was enabled. Ideally, you would always pick the safer state as the one to use as the default. However, in this case, it was impossible to say which state was safer. It is also the sort of insidious failure that does not announce itself. It is quite possible that exactly the same failure happened in many other cars, but the failure of the EEPROM was never discovered. It would go undiscovered if the car never crashed. It would also escape detection in all cases where the airbag had not been disabled by the user, because the default value picked would match the preferred value.
In other cases picking a default is just not possible. Calibration data for sensors is one example. Using median values as defaults could lead to very inaccurate operation. One option is to force the user to recalibrate the device whenever the data is lost. This sounds inconvenient, but it may be reasonable. Because calibration data would change so rarely, it is unlikely that the processor would be in the middle of writing that data when the system halted. If the system was writing calibration data when the system halted, the user must have been performing a calibration at the time. If the user was already doing a calibration, the inconvenience of doing one again will not be significant.
If calibration can only be performed at the factory, and the user can't perform calibration, the only way that the calibration data can be corrupted is by an electrical fault, or by a very specific bug, and these will be rare in comparison to system resets or power-cycles. All of this depends on the assumption that the calibration data does not share its checksum with more changeable data. If calibration data and user settings are contained in the same block, and the checksum fails, it is impossible to say which data is corrupt, necessitating that all of it be fixed. This reinforces the need to break the data into functional groups and keep a checksum for each group.
Consider Figure 1, which shows our persistent storage divided into a number of areas. If the CRC for one area fails, only that area needs to be reset to defaults, or fixed in some other way. The other values remain valid. So if we lose the Error Log, we might simply leave that area blank. However, if we lose the factory settings, the device may need to be returned to the factory to be reconfigured. I have worked on devices where the factory settings include information about what features are available on the device, so if we used a default set to rectify corruption, some customers might receive features for which they had not paid, while other customers might suddenly be missing features to which they were entitled.
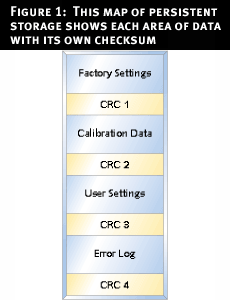
All of these compromises lead to the need for something more robust. We need a method with which our data can survive a system reset or power cycle at any time.
Double buffering
Assume we keep two copies of the data. At the point in time when the system halts, the processor could be writing to, at most, one of the copies. The copy which is not being modified will contain valid data. It has not received the latest update, but since we lost power during that update, the user's perception will probably be that the update was never entered.
There is a fisherman's adage that you should never go to sea with two clocks, since if one is wrong, how will you know which one? If the fisherman has only one clock, he is at least spared the anguish of deciding which one to trust, and then feeling that it was his own fault for trusting the wrong one when he misses the tide.
Fortunately, we can do better than the fisherman because our checksum will tell us which copy is valid. I also keep a flag that indicates which copy is the best one, as shown in Figure 2. The best flag indicates which copy to look at first. This flag has to live outside of the checksummed area.

Let's say block 0 is tagged as "best" and I want to do a write. I first make the change to block 1, and update its CRC. Then I change the best flag to indicate that block 1 is now the best one, because it contains newer data. Now I copy the data in block 1 to block 0. Once the CRC in block 0 has been updated, the best flag should be changed back to 0. If I want to do a read, I look at the best flag and then read from that block. In theory this would allow two different tasks to read and write in parallel, though in practice I have never taken advantage of this.
You may consider that there is a danger that the best flag itself could be corrupted. This is okay since the information is redundant. You could regenerate the flag's value by simply checking the checksums of each block and making sure that the flag points to one that is valid. For this reason the flag could actually live in ordinary RAM, though I find it more convenient to keep it in persistent storage.
It is necessary to ensure that the checksum of the best block is checked on reset. Another precaution worth taking is to use values other than 0 or 1 for the flag's two possible values. A corrupted device could easily be set to all zeros, so it's good to use non-zero values for the flag, which is probably going to occupy one byte of memory. It is possible that both blocks will have valid checksums, and that both are different from each other. This would occur if the reset happened just after the CRC for block 1 was written, and before block 0 was altered. Since we know that block 1 is always written first, we can assume that it contains newer data and is, therefore, the best block to use. Some programmers advocate writing one buffer as the inverse of the other buffer. This may help protect against problems such as having one data line stuck high and writing the same wrong data to both buffers, but that should be caught by the checksum in any case.
The obvious drawback of double-buffering is that it takes up twice as much space. In some cases, I only double buffer the critical data, and single buffer the data that I can afford to lose.
Double buffering will protect against any corruption due to a software failure while writing to persistent storage. However, it will not protect against a bug in your program that writes all over the memory map, possibly erasing both buffers. You can gain some protection from this by placing each buffer on separate devices, and mapping them to areas of the address space that are far apart. Serial EEPROMs have an advantage here. Because they are so difficult to write, the chances of accidentally corrupting them are slimmer than for other non-volatile memories where the block of persistent storage can be randomly accessed by the processor.
Ultimately, you cannot cover every possibility, but the goal should be to make the software as reliable as the hardware that it is using.
Trustworthy data
The technique discussed provides a basic means to ensure that persistent data is trustworthy. The exact implementation is going to depend on the size and type of persistent storage that you employ. Try to consider the software design before you finalize the circuit design, since a technique like double buffering may increase the amount of persistent storage that you need. The inconvenience of keeping a separate copy of the data in ordinary RAM might dissuade you from using a slow device such as a serial EEPROM.
In the article "How to Preserve Non-Volatile Data Across Software Versions," we will look at what happens if the software is upgraded, but we want to maintain the data in persistent memory. The ability to easily upgrade code stored in flash has made this an important topic.
Related Barr Group Courses:
Firmware Defect Prevention for Safety-Critical Systems
Top 10 Ways to Design Safer Embedded Software
Best Practices for Designing Safe & Secure Embedded Systems
Best Practices for Designing Safe Embedded Systems
Debugging Embedded Software on the Target
For a full list of Barr Group courses, go to our Course Catalog.
Endnotes
1. Sweeney, Dan. "Emerging RAM Technologies." Embedded Systems Programming, March, 2001. [back]
2. Hinerman, Dave. "Making Nonvolatile Data Reliable." Embedded Systems Programming, August, 1997. [back]
3. Williams, Ross. "A Painless Guide to CRC Error Detection Algorithms." Version 3.00, August 19, 1993. [back]
4. Barr, Michael. "Additive Checksums." [back]
5. Barr, Michael. "CRC Mathematics and Theory." [back]
6. Barr, Michael. "CRC Implementation Code in C." [back]


